Geliştiriciler İçin En İyi Önceden Eğitilmiş 7 NLP Modeli


Doğal dil işlemenin gerçek uygulamaları, önceden eğitilmiş modellerin ortaya çıkmasıyla beraber tamamen devrim etkisi yarattı. Önceden eğitilmiş modeller, sadece bu alanda yeni olan insanların uygulamalar geliştirmesine olanak sağlamayıp, aynı zamanda bu alanda uzman insanların da bir modeli sıfırdan eğitme zorunluğu olmadan daha iyi sonuçlar elde etmesine yardımcı oluyor. Önceden eğitilmiş modelleri projelere eklemek oldukça basit bir işlem olduğunu için, proje süreçlerinde çok ciddi zaman kazanımı sağlıyor. Sizlere bu yazımızda geliştiriciler için en iyi önceden eğitilmiş 7 NLP modeli listeliyoruz.
OpenAI GPT-3
GPT ve GPT-2’nin devamı niteliğinde olan GPT-3, OpenAI tarafından oluşturulan en iyi önceden eğitilmiş 7 NLP modeli listesinin ilk dil modelidir. Bu büyük ölçekli, transformatör tabanlı dil modeli, 175 milyar parametre üzerinde eğitilmiştir.
Model, çeviri, soru yanıtlama gibi birçok NLP problemlerinde güçlü performans elde etmek için eğitilmiştir. Son gelişmeleriyle beraber, haber makaleleri yazmak ve geliştiricilerin makine öğrenmesi uygulamaları yapmalarına yardımcı olan kodlar oluşturmak için bile kullanılabiliyor. GPT-3, şimdiye kadarki en büyük dil modeli olarak kabul görüyor ve etkileyici yetenekleri ile diğer tüm modelleri geride bırakıyor. Bu yıl Haziran ayında şirket, kullanıcıların yeni AI (yapay zeka) modellerine sanal olarak erişmesine izin vermek için API yayınladı.
Google BERT

BERT (Transformatörlerden Çift Yönlü Kodlayıcı Temsilleri), 2018 yılında Google tarafından geliştirilen önceden eğitilmiş bir NLP modelidir. BERT dil modelini kullanarak, Cloud TPU üzerinde 30 dakika gibi kısa bir sürede, kendi soru yanıtlama modellerinizi oluşturabilirsiniz. Şirket bu sürümle birlikte modelin, Stanford soruları veri seti de dahil olmak üzere 11 NLP görevindeki performansını sergiledi.
Diğer modellerden farklı olarak BERT, 2.5 milyon Wikipedia ve 800 milyon Book Corpus kelimesi üzerinde eğitilmiştir. Araştırmacılara göre BERT, önceki doğruluk sonuçlarını geride bırakarak %93,2’lik bir doğruluk elde etti.
Microsoft CodeBERT

Google’ın BERT framework’üne atıfta bulunan “BERT” ekine sahip Microsoft CodeBERT, çift yönlü, çok katmanlı bir sinir mimarisi üzerinde eğitilmiştir. Model, doğal dil ile programlama dili arasındaki bağlantıyı anlayarak kod arama, kod dokümantasyonu oluşturma gibi görevleri destekleyebilir.
CodeBERT, model parametrelerinde ince ayar yapılarak NL-PL ( Doğal dil ve programlama dili) görevlerinde değerlendirilmiş olup hem doğal dil hem de programlama dilinde oldukça iyi bir performans elde edilmiştir. Model ayrıca, 2.1 milyon çift modlu veri noktası ve 6.4 milyon tek modlu kod dahil olmak üzere, altı programlama dilinde Github repolarından alınan büyük veri kümeleri üzerinde eğitilmiştir.
ELMo
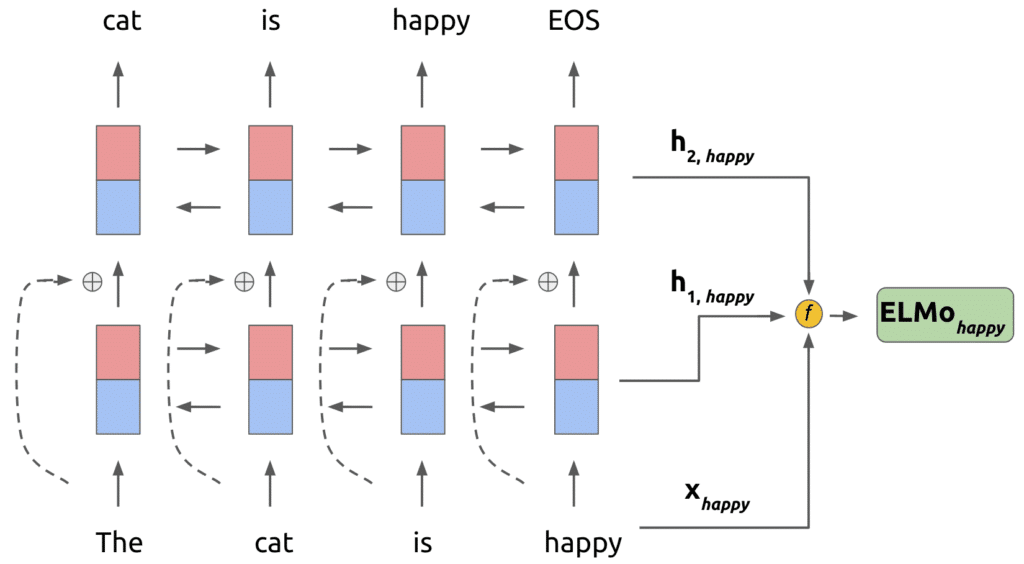
Dil Modellerinden Gömme olarak da bilinen ELMo, kelimelerin söz dizimi ve anlamsal bağların yanı sıra bunların dilsel bağlamlarını da modelleyen derin bir kelime temsilidir. Allen NLP tarafından geliştirilen bu model, büyük bir metin veri seti üzerinde eğitilmiştir. ELMo, mevcut modellere kolayca eklenebilir, bu da, soruları yanıtlama, metinsel düzenleme ve duygu analizi gibi birçok NLP problemlerini kolayca çözmenize yardımcı olur.
Google ALBERT

Google ALBERT, BERT’in bir yükseltmesi olan derin öğrenme NLP modelidir. Model, TensoFlow framework’ünde açık kaynaklı bir uygulama olarak piyasaya sürüldü. Model, birçok kullanıma hazır önceden eğitilmiş dil temsil modelleri içerir. Model ayrıca BERT modeline kıyasla sadece 12 milyon parametre içerir, yani %89 daha az olduğu anlamına gelmektedir. Ancak bu az parametre kullanımına rağmen, doğruluk oranı yaklaşık %80.1’dir.
ULMFiT

Evrensel Dil Modeli İnce Ayarı olarak da bilinen ULMFit, her türlü NLP görevini gerçekleştirmek için kullanılabilen etkili bir transfer öğrenimi yöntemidir. Model, altı metin sınıflandırma görevi üzerinde önemli ölçüde performans göstererek, veri kümelerinin çoğunda hatayı %18-24 oranında azalttı.
Ayrıca model, yalnızca 100 etiketli örnek üzerinde eğitilmiştir. ULMFiT’in yaratıcıları, geliştiricilerin kullanması için önceden eğitilmiş modelleri ve kodları açık kaynaklı hale getirdiler.
Facebook RoBERTa

Facebook geliştiricilerin yaratmış olduğu RoBERTa, BERT’in dil maskeleme stratejisi üzerine inşa edilmiş, kendinden denetimli bir NLP sisteminin ön eğitimi için optimize edilmiş bir yöntemdir. RoBERTa, BERT modelindeki temel hiperparametreleri değiştirerek, daha iyi performans elde etmeye yardımcı olan maskelenmiş dil modelleme hedefini geliştirmesine olanak tanır. Araştırmacılar ayrıca RoBERTa’yı BERT’den daha fazla veri üzerinde ve daha uzun bir sürede eğitmişler.