Duygu Analizi Nasıl Yapılır? -Doğal Dil İşleme


Duygu analizi, NLP alanında çok sık kullanılan bir yöntemdir. Herhangi bir resim, yazı ve ses dosyalarındaki görüş ve duyguların analiz edilmesidir. Özellikle şirketlerin karar verme süreçlerinde yardımcı olur. Örneğin, şirketin bir ürünü kullanıcılar tarafından çok iyi bulunmuyorsa, şirket müşteri kaybetmemek için o ürünü iyileştirip değiştirmeye ya da ürünün üretimini tamamen durdurmaya karar verir.
Duygu analizi yapmak isterseniz birçok kaynaktan veri bulabilirsiniz: halkla yapılan röportajlar, anketler ve özellikle Twitter, Facebook gibi sosyal medya platformlarında bolca duygu analizi yapabileceğiniz kaynak vardır.
Bu yazımızda ise, bir sinema filmine yapılan yorumları analiz etmeye çalışacağız.
Problem Tanımı
Amacımız, bir sinema filmine yapılan 105 değerlendirmenin olumlu,olumsuz veya nötr bir duygu içerip içermediğini tahmin etmektir. Bu, bize bir metin verildiğinde metin dizisini önceden belirlenmiş kategorilere ayırmamız gereken tipik bir denetimli öğrenme (supervised learning) görevidir.
Çözüm
Bu problemi çözmek için şöyle bir hat belirleyeceğiz:
- Verinin ve gerekli kütüphanelerin yüklenmesi
- Verinin görselleştirilmesi
- Verinin temizlenmesi
- Bag of Words (kelime çantası modeli)
- Kategorik verilerin sayısal verilere çevrilmesi
- Makine öğrenme algoritmasının kullanımı
- Test verilerinin tahminin yapılması
Python Uygulaması
Gerekli kütüphanelerinin yüklenmesi
import io,os import re import zipfile as zipfile import numpy as np import pandas as pd import seaborn as sns import matplotlib.pyplot as plt from sklearn.model_selection import train_test_split
Gerekli kütüphaneleri yükledikten sonra, .zip formatında olan verimizi ve bu veriye ait olan etiketleri yükleyebiliriz.
film_yorumlari =[]
labels=[]
with zipfile.ZipFile('film_yorumlari.zip') as z:
for zipinfo in z.infolist() :
if zipinfo.filename.endswith('.txt')and re.search('raw_texts/', zipinfo.filename):
labels.append(zipinfo.filename.split("/")[2])
with open(zipinfo.filename,"r") as f:
film_yorumlari.append(f.read())
del(f,z,zipinfo) # memory allocation
Verinin Görselleştirilmesi
Daha rahat anlaşılması için, listelerden oluşan bu verimizi Pandas kullanarak DataFrame formatına dönüştürüyoruz.
df = pd.DataFrame(list(zip(film_yorumlari,labels)),columns=['Film','Duygu'])
Veri kümemizin ilk 5 satırına bakalım.
print(df.head())

Duygu analizi dağılımlarının yüzdelik dilimini görmek için Matplotlib kütüphanesini kullanabiliriz.
plot_size = plt.rcParams["figure.figsize"] print(plot_size[0]) print(plot_size[1]) plot_size[0] = 10 plot_size[1] = 15 plt.rcParams["figure.figsize"] = plot_size df['Duygu'].value_counts().plot(kind='pie', autopct='%1.0f%%')
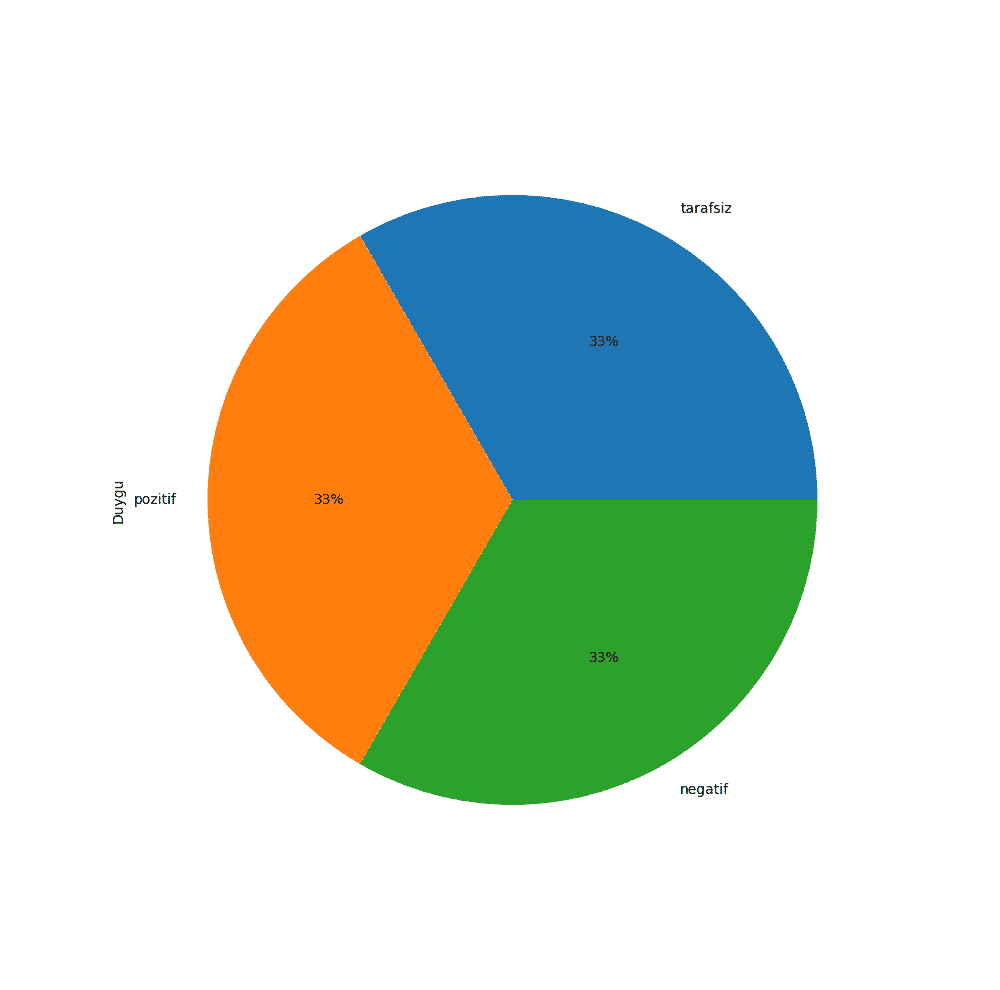
Gördüğümüz üzere, 3 duygu da eşit bir şekilde dağılmış. Sayı bazlı sonuçları görmek için de Seaborn kütüphanesini kullanabilirsiniz.
sns.countplot(df['Duygu'])
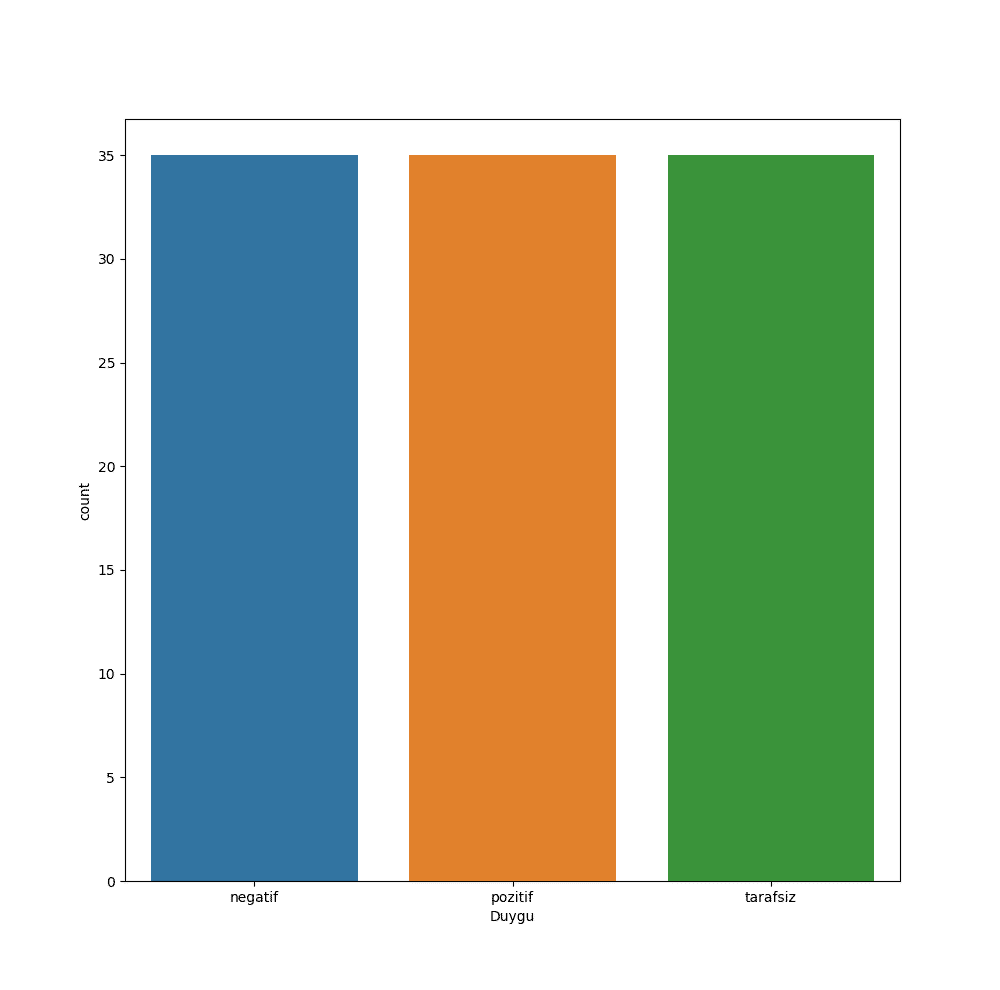
Verinin Temizlenmesi
Yukarıdaki grafikte de gördüğümüz üzere toplam 105 tane yorumun içerdiği veri setinde her duygudan 35 tane bulunmaktadır.
Bir sonraki adımımız, önceki yazımızda da bahsettiğimiz üzere cümleleri tokenlarına ayırmaktır. Bunun için Regular Expression içeren bir fonksiyon yazıyoruz. Bu fonksiyonu sonraki adımlarda verimizi temizlerken kullanıyor olacağız.
def get_tokenize(text):
acronym_each_dot = r"(?:[a-zğçşöüı]\.){2,}"
acronym_end_dot = r"\b[a-zğçşöüı]{2,3}\."
suffixes = r"[a-zğçşöüı]{3,}' ?[a-zğçşöüı]{0,3}"
numbers = r"\d+[.,:\d]+"
any_word = r"[a-zğçşöüı]+"
punctuations = r"[a-zğçşöüı]*[.,!?;:]"
word_regex = "|".join([acronym_each_dot,
acronym_end_dot,
suffixes,
numbers,
any_word,
punctuations])
return re.compile("%s"%word_regex, re.I).findall(text)
Bir sonraki adımımız ise Türkçe dilinde en sık kullanılan ve cümlenin anlamında çok etkisi olmayan stopwords dediğimiz kelimeleri tanımlamaktır. Yine bir sonraki adımda verimizi temizlerken de bu stopwordsleri de kullanıyoruz olacağız.
stopwords= frozenset(["acaba","ama","ancak","arada","bana","belki","ben","benden",
"beni","bence","benim","beri","bile","bi","bin","bir","biraz","biri","birkez",
"biz","bize","bizden","bizim","böyle","bu","buna","bunda","bundan",
"bunlar","bunu","bunun","burada","çok","da","daha","dahi","de","değil","defa",
"diye","doksan","edecek","eden","ederek","edilecek","ediliyor",
"ediyor","elli","en","etmesi","etti","fakat","gibi","halen","hangi",
"hatta","hem","hep","hepsi","her","herhangi","herkesin","için","iki",
"ile","ilgili","ise","itibaren","itibariyle","kadar","kendi",
"kendilerine","kendini","kendisi","kendisine","kez","ki","kim",
"kimden","kime","kimi","kimse","milyar","milyon","mu","ne",
"neden","nedenle","nerde","nerede","nereye","niye","olan",
"olarak","oldu","olduğu","olduğunu","olmuş","olmak","olmayan","olmaz","olsa","olsun",
"olup","olur","olursa","oluyor","on","ona","ondan","onlar",
"onlardan","onu","onun","oysa","öyle","pek","sadece","sanki","sekiz",
"sen","senden","seni","senin","siz","sizden","sizi","sizin","sonra","şey","tam","tek","tüm",
"var","var.","ve","veya","ya","yani","yapacak","yapmak","yapılmış","yok","yok.","yine","yoksa",
"zaten",".",",",":",";","?","!","i","o"])
Şimdiki adımımız ise verimizi temizlemek olacak. Bunun için clean_text() adını verdiğimiz bir fonksiyon yazıp, yukarıda tanımladıklarımızı da bu fonksiyona dahil ediyoruz. Bu fonksiyonda yapılan iş oldukça basittir. Her bir film yorumunu önce küçük harflere dönüştürüyoruz, daha sonra tanımladığımız get_tokenize() fonksiyonunu kullanarak cümlemizi tokenlarına ayırıyoruz. Sonraki adımda ise, eğer bu tokenlar yukarıdaki stopwords listesinde bulunmuyorsa, fonksiyon içinde tanımlamış olduğumuz cleaned_text adlı listeye ekliyoruz.
def clean_text():
cleaned_text = []
for yorum in film_yorumlari:
yorum = yorum.lower()
yorum = get_tokenize(yorum)
yorum = [y for y in yorum if not y in stopwords]
cleaned_text.append(yorum)
return cleaned_text
cleaned_text = clean_text()

Verimizi de temizledikten sonra, sıradaki adım en sık geçen 30 kelimeyi tespit etmektir. Bunu yapmamızın sebebi, birazdan bahsedeceğim Bag Of Words (Kelimelerin Çantası) modelini uygulayacak olmamızdan dolayıdır.
Bu işlemi yapmak için create_word_freq() fonksiyonunu kullanıyor olacağız. Bu fonksiyonda boş bir sözlük oluşturuyoruz. Eğer cümlelerin içinde tokenlar sözlüğün içinde bulunmuyorsa token=1 diyoruz fakat daha önceden o token sözlük içinde bulunuyorsa mevcut değerini 1 artıyoruz.
def create_word_freq(corpus,n):
word_freq = dict()
for tokens in cleaned_text:
for token in tokens:
if token in word_freq.keys():
word_freq[token] +=1
else:
word_freq[token]=1
most_freq = sorted(word_freq.items(),key=lambda x:x[1],reverse=True)
return dict(most_freq[:n])
most_freq =create_word_freq(cleaned_text,30)

Belki de bir önceki yazımızı okuduysanız, gözünüze çarpan bir şey olmuş olabilir. O da, “film”, “filmi”, “filmin” gibi kelimelerin kökünün “film” olduğu ve lemmatizasyon işleminin yapılması gerektiğidir. Python’da Türkçe metne bu işlemi uygulamak için herhangi bir araç henüz bulunmamaktadır, o yüzden şimdilik o işlemi es geçiyor olacağız.
Bag of Words (Kelimelerin Çantası)
En önemli kısım olan, Bag of Words (Kelimelerin Çantası) modelini yapacağız. Mantık olarak çok basit ve aslında eski bir yöntemdir. Satırları metindeki cümlelerimiz, sütunları ise az önce belirlediğimiz en çok tekrar eden kelimeler olan bir matris düşünelim. En çok tekrar eden kelimelerin cümleler içinde olup olmadığına bakalım. Eğer var ise 1 yok ise 0 olarak işaretleyelim.
Bir örnekle daha iyi anlaşılacaktır:
En çok tekrar eden kelime olan “film” kelimesini alalım. Daha sonra bu kelimenin ilk cümlede olup olmadığını kontrol ediyoruz.
İlk cümlemiz ise:
“Senariste lafım Rain Man filmini taklit ederek senaryo yazılmaz. Yönetmene lafım, filmin sonunda milleti ağlatmak için türlü şaklabanlıklara girilmez. Son olarak yağmur sahnesini millet anlamaz bak ben bunu itfaiye hortumuyla sağlıyorum görün diye gösterilmez. Tüm bunları göremeyen izleyiciler de, sakın bana film harika demesin”.
Görüldüğü üzere, ilk cümle “film” kelimesini içermektedir. Bu yüzden birinci sütunun birinci satırını 1 olarak işaretliyoruz. Bunu her cümle ve her kelime için yaptığımızda ortaya şöyle bir sonuç çıkıyor:
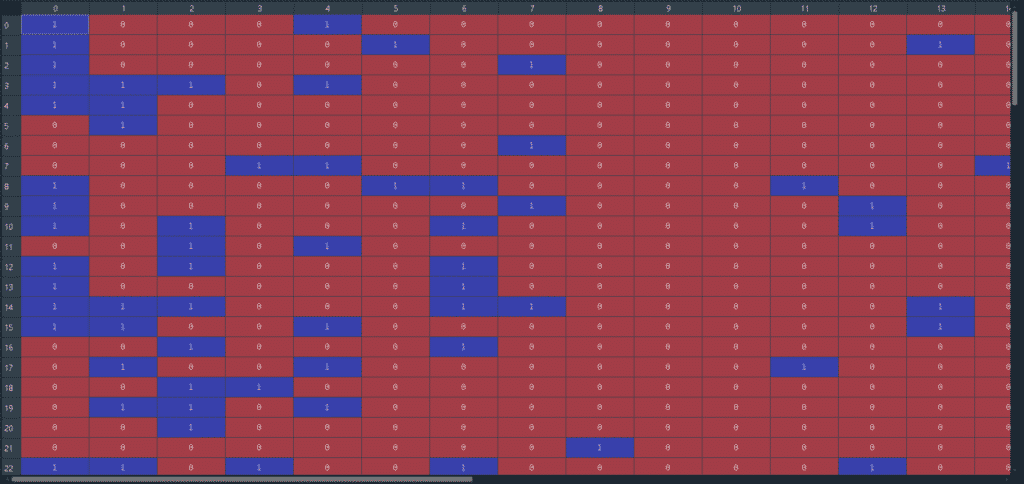
Bu gördüğümüz matrisi ise şu kodu yazarak yapabiliyoruz:
def create_bow(corpus):
sentence_vectors = []
for tokens in cleaned_text:
sent_vec=[]
for word in most_freq:
if word in tokens:
sent_vec.append(1)
else:
sent_vec.append(0)
sentence_vectors.append(sent_vec)
sentence_vectors = np.asarray(sentence_vectors)
return sentence_vectors
bow = create_bow(cleaned_text)
Kategorik Verilerin Sayısal Verilere Çevrilmesi
Makine öğrenmesi modelimizi yazmadan önce yapacağımız son işlem, duyguları kategorik değerlerden sayısal değerlere çevirmek. Yani negatif için 0, nötr için 1 ve pozitif için 2 değerlerini atayacağız. Bu işlemi list comprehension kullanarak tek satırda yazabiliriz.
labels = np.asarray([0 if label=="negatif" else 1 if label=="pozitif" else 2 for label in labels]).reshape(-1,1)
Veri setimizi train ve test olmak üzere iki parçaya ayırıyoruz. Bunun için sklearn kütüphanesini kullanmamız gerekiyor. 105 tane veri içeren bu seti, 94 tanesi train ve 11 tanesi test olacak şekilde ayırıyoruz.
Makine öğrenimi modeli ve test verilerinin tahmini
x_train,x_test,y_train,y_test = train_test_split(bow,labels,test_size=0.1,random_state=42)
Bu işlemi de tamamladıktan sonra sıra, bir makine öğrenmesi modeli eklemektir. Bunun için herhangi bir makine öğrenmesi kütüphanesi kullanmadan yazdığımız KNN(En yakın K komşu) algoritması olacaktır.
def euclidean_distance(x1, x2):
return np.sqrt(np.sum((x1 - x2)**2))
def _predict(x_test,k):
distances= [euclidean_distance(x_test, x_) for x_ in x_train]
distances = np.asarray(distances)
k_indexs = np.argsort(distances)[:k]
k_neighbours_labels = [y_train[i] for i in k_indexs]
counts=dict()
for i in k_neighbours_labels:
for j in i:
if j in counts.keys():
counts[j]+=1
else:
counts[j]=1
most_freq = sorted(counts.items(),key=lambda x:x[1],reverse=True)
return most_freq[0][0]
def predict(test,k):
predictions=[]
for i in test:
predictions.append(_predict(i,k))
return np.array(predictions)
predictions = predict(x_test,6).reshape(-1,1)
accuracy = np.sum(y_test == predictions)/len(y_test)*100
print(accuracy)
K değerini sezgisel bir şekilde seçebilirsiniz. K değerini 6 seçtiğimiz taktirde doğruluk oranı %45.45 olacaktır. Aslında oldukça düşük bir sayıdır, bunun belli başları sebepleri vardır. Veri miktarının az olması, lemmatizasyon yapılmaması vb. gibi.
Bu modelde yapacağımız son şey belli başlı K değerleri için hangi doğruluk oranını aldığımızdır.
score_list = []
for each in range(1,10):
prediction =predict(x_test,each).reshape(-1,1)
accuracy = np.sum(y_test == prediction)/len(y_test)*100
score_list.append(accuracy)
plt.plot([each for each in range(1,10)],score_list)
plt.xlabel("Number of K")
plt.ylabel("Score List")
plt.show()
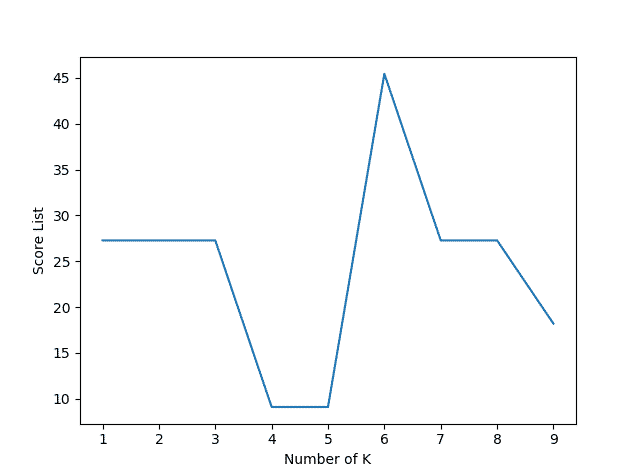
Grafikte de gördüğümüz üzere, en yüksek skor K değeri 6 iken görülmüştür.
Duygu analizi, doğal dil işleme konusu bakımından oldukça faydalı bir yöntemdir. İnsanların memnuniyet derecelerini kategorize ederek aslında ürün ve proje oluşturucuları için nasıl gelişebilecekleri yönünde bir kılavuz görevi görüyor. Böyle bir analiz yönteminin varlığı bile gelecekte birçok konuda gelişim ve iyileştirme sağlanması için açık bir kapı bırakıyor.