TwitterScraper Nedir? Nasıl Kullanılır? - Python Kütüphanesi


TwitterScraper, Twitter’dan herhangi bir konu ile ilgili tweet çekmek için yazılmış bir Python kütüphanesidir. Peki bu çekilen tweetler ile ne yapabiliriz? Aslında bu kullanım amacına göre değişiklik gösteren bir şeydir. “Duygu Analizi Nasıl Yapılır? “ yazımızda duygu analizi yapmak için Twitter, Facebook gibi birçok sosyal medyada veri bulunduğunu söylemiş fakat bunların nasıl kullanılacağına dair bir şey söylememiştik. Bu yazımızda ise duygu analizi için gerekli olan veriyi Twitter’dan nasıl çekeriz, bunu öğreniyor olacağız.
Twitter, geliştiricilere verilerine erişmek ve kullanmak için REST API ve bunun yanı sıra, verilere gerçek zamanlı erişmek için kullanılabilecek bir Streaming API da sağladı.
Twitter verilerine erişmek için yazılan yazılımların çoğu API (uygulama programlama arayüzü) gerektirir. Bu da beraberinde bir sınırlama getirir. Ayrıca bu API’lara erişmek de hızlıca halledilebilecek bir şey değildir. Geliştirici olarak Twitter’a başvurmanız ve bu verilere erişmek için geçerli bir sebebiniz olmalıdır.
Twitter’ın arama API’ı ile her 15 dakikada bir yalnızca 180 istek gönderebilirsiniz. İstek başına maksimum 100 tweet, saatte ise 4 X 180 X 100 = 72.000 tweet alabileceğiniz anlamına gelir. Twitterscraper ile bu sayıdan bağımsız, internet hızınız ve bant genişliğiniz yeterli olduğu sürece istediğiniz kadar veri çekebilirsiniz.
Twitter Arama API’sının diğer büyük bir dezavantajı ise, yalnızca son 7 gün içinde yazılan tweetlere erişebiliyor olmanızdır. Bu, modelinde eski verilere yer vermek isteyenler için oldukça can sıkıcı bir durumdur. Twitterscrapper ile böyle bir sınırlama da yoktur.
Kurulumu
TwitterScraper’ı yüklemek için aşağıdaki kodu çalıştırmanız gerekmektedir.
pip install twitterscraper
Diğer bir yol ise, GitHub deposunu indirip ardından aşağıdaki kodu çalıştırmaktır.
python setup.py install
Eğer Docker kullanıyorsanız:
docker build -t twitterscraper:build
ve Docker Container’ınızı şu komutla çalıştırabilirsiniz:
docker run --rm -it -v/<PATH_TO_SOME_SHARED_FOLDER_FOR_RESULTS>:/app/data twitterscraper:build <YOUR_QUERY>
Komut Satırı
Aşağıdaki kodu komut satırında çalıştırarak tweetleri JSON (Javascript Nesne Gösterimi) formatında saklayabilirsiniz.
twitterscraper "Trump OR Clinton" --limit 100 --outputs=tweets.json
Limiti istediğiniz gibi değiştirebilir ve tweetleri arama sırasında Ctrl + C tuşlarına basarak arama işlemini iptal edebilirsiniz. İşlem tamamlandıktan sonra ise çekilen tweetler JSON dosyanızda güvenle saklanır.
Python Kodu
Her yazımızda değindiğimiz gibi, tabi ki bu yazımızda da Python koduna yer vereceğiz. Haydi başlayalım!
Gerekli kütüphaneleri yüklemekle başlayabiliriz:
from twitterscraper import query_tweets import datetime as dt import pandas as pd
Gerekli kütüphaneleri yazımızın ilerleyen kısmında detaylıca açıklıyor olacağız. Sıradaki adıma geçebiliriz.
query_tweets() modülümüz parametre olarak şunları alır:
- limit: Verilen limit sayısına ulaşınca veri çekme işlemini durdurur. Veriler 20’lik gruplar halinde alındığından, bu her zaman 20’nin katı olacaktır. Belirlediğiniz limite ulaşmadan Ctrl + C tuşlarına basarak çekme işlemini durdurabilirsiniz.
- lang: Belirlenen dildeki verilere erişir. Şu anda 30’dan fazla dil tarafından desteklenmektedir. Tam liste için help mesajını yazdırabilirsiniz.
- begindate: Belirlediğiniz tarihten itibaren veri çekmeye başlar. Formatınız YYYY-AA-GG şeklinde olmalıdır. Bu parametrenin varsayılan değeri 2006-03-21 dir.
- enddate: Belirlediğiniz tarihlere kadar olan verileri çeker. Formatınız YYYY-AA-GG şeklinde olmalıdır. Bu parametrenin varsayılan değeri bugündür.
- query: Hakkında arama yapmak istediğiniz kelimeyi string halinde yazınız.
TwitterScraper için parametre değerlerimizi tanımlayabiliriz. Ben bu Python uygulamasında “Atatürk” ile atılmış tweetleri çekmek istiyorum ve DateTime kütüphanesini kullanarak başlangıç ve bitiş günlerimi belirliyorum.
limit = 1000 begin_date = dt.date(2019,4,15) end_date = dt.date(2019,4,18) lang = "turkish" query = "Atatürk"
Parametreleri de tanımladıktan sonra, artık tweetleri çekme aşamasına geçebiliriz.
ataturk= query_tweets(query,begindate=begin_date,enddate=end_date,limit=limit,lang=lang)
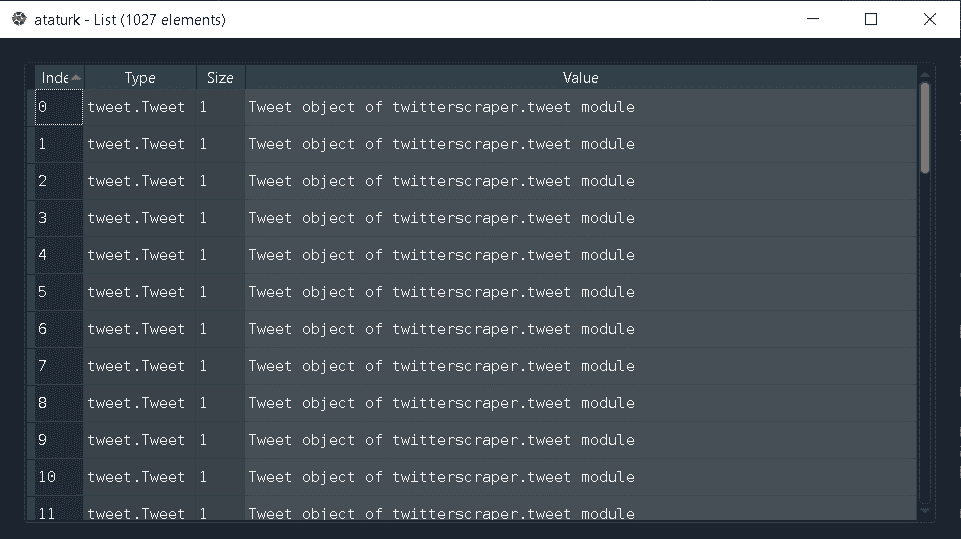
Yukarıda da göreceğimiz gibi 1027 tane tweeti çektik, fakat tweetler şuan Tweet objesi olarak gözüküyor. Pandas kütüphanesini kullanarak DataFrame’e dönüştürüyoruz.
df_ataturk = pd.DataFrame(t.__dict__ for t in ataturk)
Dönüştürdükten sonra ortaya 21 sütunlu bir DataFrame ortaya çıktı. Bu sütunlar:
df_ataturk.columns OUTPUT: Index(['screen_name', 'username', 'user_id', 'tweet_id', 'tweet_url', 'timestamp', 'timestamp_epochs', 'text', 'text_html', 'links', 'hashtags', 'has_media', 'img_urls', 'video_url', 'likes', 'retweets', 'replies', 'is_replied', 'is_reply_to', 'parent_tweet_id', 'reply_to_users'], dtype='object')
Ben DataFrame’de sadece tweetleri almak istiyorum, bunun için bir filtreleme işlemi yapmam gerekiyor.
df = df[['text']]
İlk 6 tweetimize bakalım.

Sonuç olarak, Twitter’dan veri çekmek için API’a gerek duymadan, Twitterscraper kütüphanesini kullanarak halletmiş olduk. Parametreler değiştirilerek daha da farklı sonuçlar elde edilebilir.