Regular Expression Nedir? Yeni Başlayanlar İçin Regex


Regular Expression (Düzenli İfadeler) bir dizi içerisinde belli kalıpları bulmaya yarayan bir sembol kümesidir. Sıkça programlama dili ile karıştırılsa da bir programlama dili değildir.
Regular Expression Tarihçesi
Regular Expression’ı daha iyi kavramak adına onun çıkış noktasına birlikte bakalım. Bu kavram bilgisayar biliminden ortaya çıktı sanılsa da, aslında sinir bilimi alanından esinlenilmiştir.
McCulloch ve Pitts’in insan sinir sistemi üzerinde geliştirdikleri model ile başlayan Stephen Kleene’in çalışmalarıyla daha da gelişen model, cebirsel formüllerden oluşmaktadır. Klenee, sonrasında bu modeli regular set (düzenli ifade) olarak tanımlamıştır.
Ken Thompson adlı matematikçi, UNIX’i (işletim sistemi) geliştiren önemli isimlerden biri olararak, ed adlı bir metin editör’ünün içine regex’i eklemiştir. Bu editörde bazı basit işlemler gerçekleştirilebilmektedir. Mesela bir metnin içerisinde geçen kırmızı kelimesini aramak gibi fonksiyonlara sahiptir. İşte bu sayede regex bilgisayar dünyasına ilk adımını atmış oldu, teşekkürler Ken Thompson!


Regular Expression Nedir?
Regular Expression yazı modelleri kullanarak yazılar içinde arama yapmamızı sağlayan bir dizi semboldür. Bu yazı modellerini haber, e-mail, hikaye, mesajlar, bilgisayar kodları, telefon rehberi gibi veriyle ilgili her yerde kullanabilir ve görebiliriz. Bu verileri işleyen bir işlemci gibi onlar üzerinde arama, eşleşme, değiştirme yapabiliriz.

Regular Expression Kullanım Alanları
Bazı kullanım alanlarını sizler için listeledik:
- Bir mail adresi doğru formatta mı diye test etmemizi sağlar.
- Bir posta kodu doğru sayıda rakam içeriyor mu test etmemizi sağlar.
- Acaba kelimesindeki tüm a harflerini i harfine çevirebilmemizi sağlar.
- Bilimi kelimesinin kaç kez sinir, bilgisayar, felsefe kelimelerinin ardından kullanıldığını bulmamızı sağlar.
- Bir yazı içinde tekrar etmiş kelimeleri bulmamızı sağlar.
- Bir klasör içinde aynı dosya uzantılarına sahip dosyaları bulup, uzantıyı değiştirmeyi sağlar.
- Dosya ismi içindeki tüm noktaları boşluğa çevirmemizi sağlar.
Kısacası regular expression’ı, arama motorları, veri analizi, doğal dil işleme, kod editörleri gibi birçok alanda görebilmekteyiz. Bir kez öğrenildiği takdirde ne kadar çok işe yarayacağı örneklerden de anlaşılmaktadır.
Bir başka alandan örnek vermek gerekirse, Biyoenformatik (biyoloji ve bilgisayar bilimi) biliminde DNA, protein dizilimlerini takip etme konusunda da regex kullanılmaktadır. İnsan DNA’ları belli bir deseni takip etmek zorundadır. Desende bir eksiklik sonucu bazı hastalıklar doğabilmektedir. Bu alanda incelemeler yapan bu bilimde regex aktif bir şekilde kullanılmaktadır.
Regex Araçları:
Regex araçları regex işlemleri yapmamız için geliştirilmiş programlama ara yüzleridir. Genel olarak birbirine benzer yapıya sahip olsalar da aralarında küçük bazı farklılıklar olduğunu dile getirebiliriz. Sizler için bazı popüler araçları listeledik:
- GNU ERE
- JavaScript Regex Engine
- PCRE
- Perl
- PHP preg
- XRegexp2
- C# Regex Engine
- Java Regex Engine
Yeni Başlayanlar İçin Regex
Bilinmesi Gereken Bazı Kavramlar
Preceding (Önce Gelme)
Bir düzende herhangi bir harf ya da sembolden önce gelen demektir. Bunu bir örnekle açıklayalım:
Elma*Bu kelimede a karakteri yıldız’dan önce gelmektedir. E karakteri de l karakterinden önce gelmektedir.
Following (Sonra Gelme)
Bir düzende herhangi bir harf ya da sembolden sonra gelen demektir. Bunu bir örnekle açıklayalım:
*ElmaBurada E karakteri yıldız’dan sonra gelmektedir. Yine a karakteri de m karakterinden sonra gelmektedir.
Escaping (Kaçış)
Regex’in içinde özel karakterlerin yer aldığı sembol kümesi olduğunu söylemiştik. Bu karakterler metinlerde de kullanığımız [ ] ? % + ^ gibi semboller olabilmektedir. Bu semboller metinde regex mi belirtiyor, yoksa metnin kendi düzeninde mi var, bunu ayırt etmekte fayda var. Yoksa istediğimiz sonucu elde edemeyiz.
Bu nedenle escaping karakter dediğimiz \ ters bölü işaretini kullanıyoruz.
Bununla ilgili örnekler ileri adımlarda verilecektir.
Regex Başlangıç Rehberi
Verdiğimiz örnekleri online bir şekilde test etmek istiyorsanız regex101 adlı siteyi kullanabilirsiniz.
String Matching (Dizi Eşleme)
Bir yazıda istediğiniz kelimeyi yazıp sonuca göre eşlemenin yapıldığı eylemdir. Bir örnekle açıklayalım:
Bugün diğer günlerin aksine güne mutlu ve huzurlu başlamıştım. Tek dilediğim günün geri kalanını da bu şekilde geçirmekti. Regex Eylemi:
günSonuç:
Bugün diğer günlerin aksine güne mutlu ve huzurlu başlamıştım. Tek dilediğim günün geri kalanını da bu şekilde geçirmekti.
Gördüğünüz gibi metinde gün ile eşleşen tüm kelimeleri bulmamızı sağladı.
OR Operator (Veya İşlemi)
Veya işlemi verilen seçeneklerden hangisi ya da hangileriyle eşleşiyorsa, bize o sonuçları getirmektedir.
Dün geceki futbol maçının ardından tribünden kaçışan insanlardan bazıları saç baş kavgaya giriştiler.(s|m|k)açDün geceki futbol maçının ardından tribünden kaçışan insanlardan bazıları saç baş kavgaya giriştiler.
Bizim istediğimiz aç ekinin başta belirttiğimiz s,m,k harfleriyle başladığı müddetçe eşleşmesiydi. Sonuçta da eşleştiğini görüyoruz.
Aynı işlemi bu şekilde de yapabilirdik.
[s|m|k]açBu şekilde de sonuç aynı olurdu.
Ranging & Bracket Expressions (Aralık Ve Parantez İşlemleri)
[a-z] -> a'dan z'ye tüm harfleri eşle. (küçük harfler)
[A-Z] -> A'dan Z'ye tüm harfleri eşle. (büyük harfler)
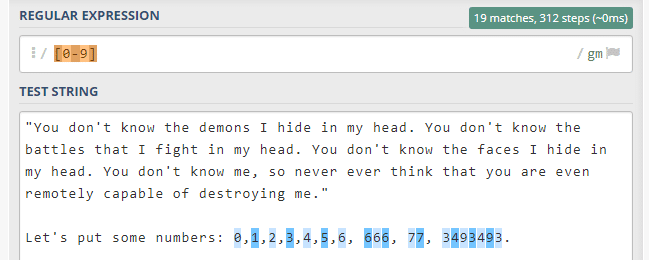
[0-9] -> 0'dan 9'a tüm sayıları eşle.
Birleşmiş Halleri:
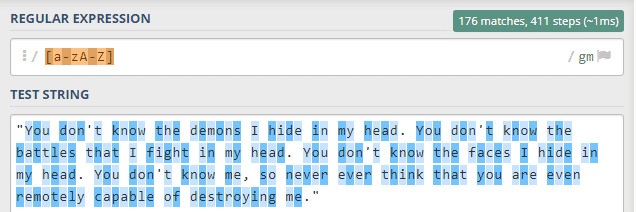
[a-zA-Z] -> Tüm harfleri eşle. (küçük ve büyük harflerin hepsi.)
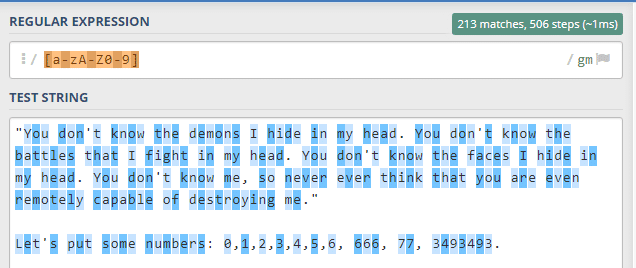
[a-zA-Z0-9] -> Tüm harfleri ve sayıları eşle. (küçük ve büyük harfler ve sayıların hepsi)Bunları tek tek örneklerle anlatalım.
İlk örneğimizde küçük harfle başlayan tüm harflerin eşleşmesini istedik. Gördüğünüz gibi büyük harfler, nokta, tırnak işareti, boşluk dışında kalanlar yani küçük harfler bulundu.
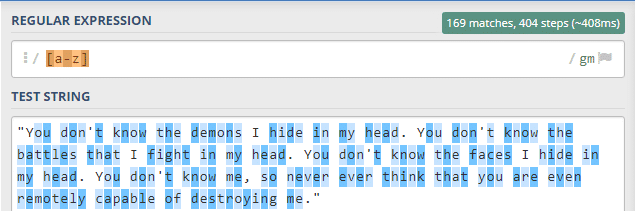
Aynı örneği büyük harfler için yaptığımızda bu sefer yazının içindeki büyük harflerin seçildiğini görüyoruz.
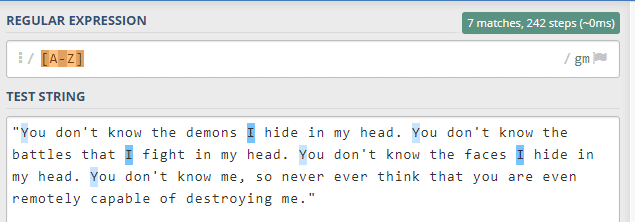
Eğer küçük ve büyük harfleri aynı anda yakalamak istiyorsak ikisini de birleştirip yazabiliriz. Sonucunda da gördüğünüz gibi hepsi seçilmiş olur.
Eğer rakamların seçilmesini istiyorsak bu sefer [0-9] eylemiyle yazının içindeki rakamları seçebiliriz. Gördüğünüz gibi rakamlar haricindekiler seçilmedi.
[a-zA-z0-9] eylemini denersek yazının içindeki büyük, küçük harfler ve bunlarla birlikte rakamları da seçtiğimizi görebiliriz.
Quantifiers (Nicelik Belirleyiciler)
evet* -> 'eve' ile başlayan ve devamında t karakterinden hiç ya da bir/birden fazla içerenleri eşler.
evet+ -> 'eve' ile başlayan ve devamında t karakterinden en az bir veya birden fazla içerenleri eşler.
evet? -> 'evet' ya da 'eve' yi eşler. t karakteri opsiyoneldir.
evet{3} -> art arda üç t içeren kelimeler ile eşlenir.
evet{2,} ->art arda iki t ya da daha fazlasını içeren kelimeler ile eşlenir.
evet{2,4} -> art arda iki ve dört rakamları aralığında t içeren kelimeler ile eşlenir.Şimdi bu regex eylemlerini örneklerle kavrayalım.
İlk örneğimizde evet kelimesinin sonunda yıldız eylemini görüyoruz. Bu eve, evet, evett diye giden tüm kelimeleri eşleştirmektedir. ‘eve’ ile başlayıp 0 veya sonsuza giderek t içeren tüm kelimeleri kapsayacaktır.
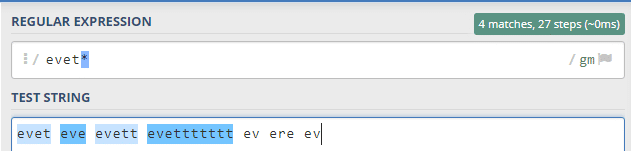
Bu örneğimizde evet kelimesini + eylemiyle görmekteyiz. Bu eylemde kelimenin en az bir tane t içermesi zorunludur. Bu bağlamda içinde eve geçen ve en az bir tane sonunda t bulunan kelimeleri eşleştirmektedir.
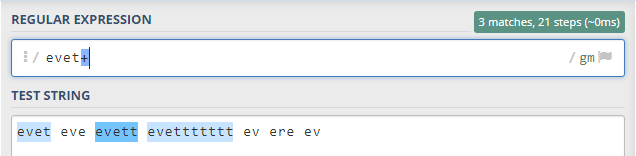
Bu eylemde ise eve ya da evet kelimelerini eşleştiren ? ‘ni görüyoruz. Yıldızın aksine diğer t’leri almadığını fark edelim. o zaman sadece eve ya da evet olanları alacaktır.
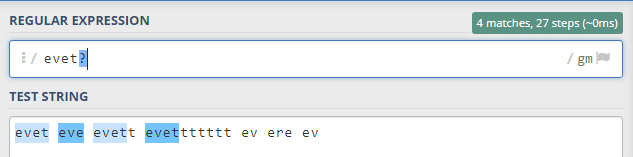
Bu örnekte ise eve kelimesini takip ederek üç t içeren kelimeleri eşleştirdiğini görüyoruz.
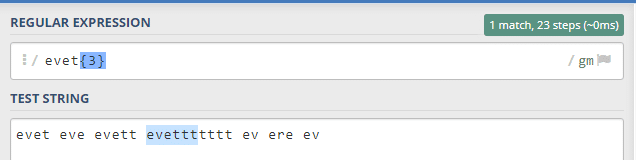
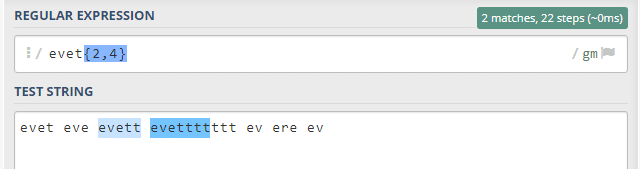
Bu örneğimiz de ise eve kelimesini takip eden iki ve dört aralığında t sayısına sahip kelimelerin eşleştiğini görmekteyiz. Bu örnek evett, evettt ve evetttt örneklerini kapsar. 2 ve 4 bu kümenin içine dahildir.
Character Classes (Karakter Sınıfları)
\d -> Herhangi bir sayı ile eşler.
\w -> Herhangi bir harf veya sayı eşler. Karşılığı bu ifadedir: [a-zA-Z0-0]
\s -> Herhangi bir boşluk ile eşler. Bu ifadeleri kapsamaktadır: \r:Carriage Return (satır başı), \n:new line(yeni satır), \t:(tab).
. -> Tüm harfler, sayılar, karakterler ve boşluk ile eşlenebilir.
\D -> \d 'nin tam tersini yani sayı dışındaki her şey ile eşleşir.
\W -> \w 'nin tam tersini yani harf ve sayı dışındaki her şey ile eşleşir.
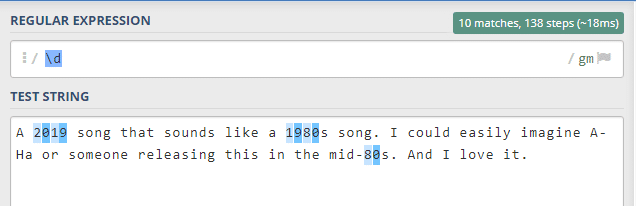
\S -> \s ' nin tam tersini yani tab, yeni satır gibi boşluk ifadeleri dışındaki her şey ile eşleşir.İlk örneğimizle başlayalım. \d örneği sadece sayılarla eşleşir demiştik. Gördüğümüz gibi metindeki sayılar yakalanmış durumda.
Yazıda escaping karakterden söz etmiştik, burada kullandığımızın altını çizelim. Eğer sadece d harfini kullansaydık metin içindeki d’leri yakalardı. Bu nedenle \ eki ile onun regular expression’a ait bir eylem olduğunu belirtiyoruz.
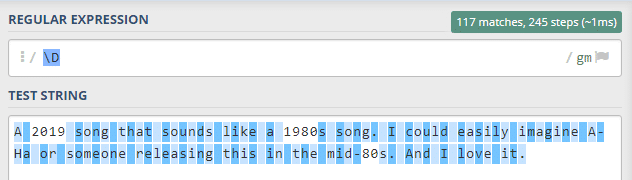
\D örneğimiz \d nin zıttı olarak rakam olmayan her şey ile eşleşmektedir.
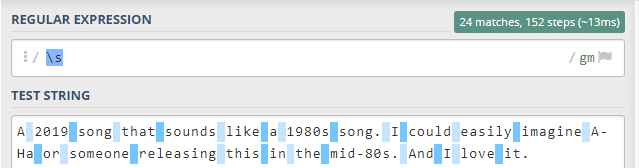
Metindeki yeni satır, tab gibi tüm boşluk türlerini kapsayan \s eyleminin metindeki sonucunu görmekteyiz.
\S ise boşluk olmayan her şeyi yakalayan bir eylemdir. Görüldüğü üzere boşluk hariç her şey eşleşmiştir.
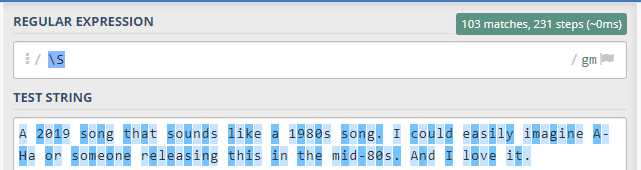
\w adlı eylem metinde büyük, küçük harfleri ve sayıları kapsamaktadır. [a-zA-Z0-9] ile aynı anlama sahiptir.
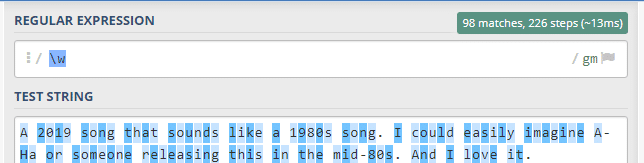
\W ise metindeki boşlukları ve karakterleri yakalayan bir eylemdir. ‘.’, ‘-‘ gibi karakterlerin de seçildiğinin altını çizelim.
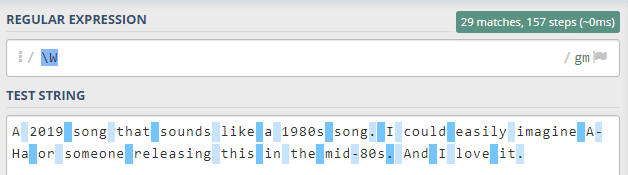
Anchors ^ and $ (Baş ve Son)
Diyelim ki yüzlerce metin arasında sadece www ile başlayan ve sonu com eki ile biten kelime parçacıklarını yakalamak istiyoruz. Bu kelimeleri yakalamak için kelime başını ve sonunu belirleyen eylemlere ihtiyacımız var.
^ ve $ tam da burada karşımıza çıkıyor. ^ eylemi cümle başını ve de $ eylemi cümle sonunu ifade etmektedir.
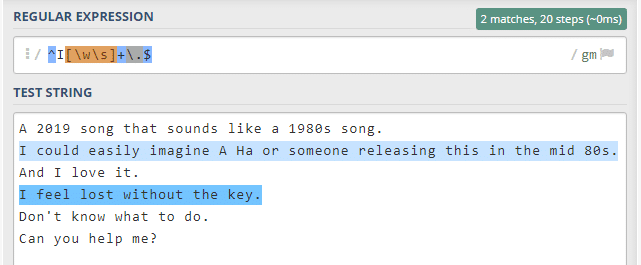
Örneğimize bakalım. İlk başta [\w\s] kısmından bahsedelim.
\w harf ve sayıların tamamını kapsıyordu. \s ise boşlukların tamamını içeriyordu.
Sadece bunu kullanmış olsaydık metindeki tüm harf ve boşlukları yakalamış olurduk.
Fakat biz baş harfi I ile başlayan cümleleri almak istiyoruz. Bu nedenle ^I ekleyerek bu isteğimizi dile getiriyoruz.
+ kullanma nedenimiz ise [\w\s] en az bir ya da daha fazla eşleşme olmasını istememiz.
Bu sayede cümlenin tamamını alıyoruz. Fakat eksik görünen bir şey var gibi. Cümledeki noktalar dahil olmamış. O halde cümle sonuna bakalım.
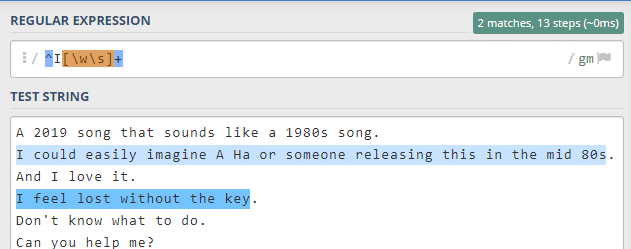
Bu sefer cümle sonunda nokta aradığımızı belirtmek istiyoruz. ‘\.’ (yine bir escaping karakteri, nokta herhangi karakterle eşleş olduğu için) ve ardından $ ile artık nokta da dahil oldu.