Pandas Nedir? Nasıl Kullanılır? - Python Kütüphanesi


Pandas, “ilişkisel” ve “etiketli” verilerle çalışmayı kolay ve sezgisel hale getirmek için tasarlanmış hızlı, esnek ve etkileyici veri yapıları sağlayan bir Python paketidir. Python’da pratik, gerçek dünya veri analizi yapmak için temel yapı taşı olmayı hedefler. Ayriyeten, her dilde mevcut olan en güçlü ve esnek açık kaynak veri analizi / manipülasyon aracı olmak gibi daha geniş bir amaca sahiptir.
Pandas, bir çok farklı veri türü için uygundur:
- SQL tablosunda veya Excel tablosunda olduğu gibi, heterojen şekilde yazılan sütunlara sahip tablo verileri
- Sıralı veya sırasız (sabit frekansta olmayabilir.) zaman serisi verileri
- Satır ve sütunlarındaki ardışık matris verileri (homojen ya da heterojen)
- Herhangi bir gözlemsel/ istatistiksel veri kümesi. Pandas’ın veri yapısına yerleştirilmek için verilerin etiketlenmesi gerekmez.
Pandas’daki iki temel veri yapısı olan, Seriler( 1 boyutlu) ve DataFrame( 2 boyutlu), finans, istatistik, sosyal bilimler, bir çok mühendislik alanındaki tipik kullanım durumlarının büyük çoğunluğunu ele alır. Pandas, NumPy’ın üzerine inşa edilmiş bir pakettir ve diğer bir çok üçüncü parti kütüphanesiyle bilimsel işlem ortamına iyi bir şekilde entegre olmayı amaçlamaktadır.
Pandas’ın iyi yaptığı şeylerden sadece birkaçı:
- Kayıp verilerin (NaN olarak temsil edilir) kolayca işlenmesi
- Boyut değiştirilebilirlik: DataFrame ve daha yüksek boyutlu nesnelerden sütunlar eklenebilir veya silinebilir.
- Otomatik ve belirgin veri hizalama: Nesneler bir etiket kümesine acıkça hizalanabilir veya kullanıcı etiketleri görmezden gelebilir ve Seri,DataFrame vb.nin hesaplamalarda sizin için verileri otomatik olarak hizalamasına izin verir.
- Verileri toplamak ve dönüştürmek için veri kümelerinde böl-uygula-birleştir işlemlerini gerçekleştirmek için güçlü ve esnek “group by” işlevine sahiptir.
- Diğer Python veya NumPy veri yapılarındaki düzensiz, farklı dizinlenmiş verileri DataFrame nesnelerine dönüştürmeyi kolaylaştırır.
- Veri kümelerinin kolayca yeniden şekillendirilmesi
- Eksenlerin hiyerarşik etiketlenmesi (işaret başına birden çok etiket olması mümkündür.)
- Zaman serisine özgü işlevsellik: tarih aralığı oluşturma ve frekans dönüştürme, hareketli pencere istatistikleri, tarih kaydırma ve geciktirme
Bu maddelerin çoğu, bilimsel araştırma ortamlarında sıkça karşılaşılan eksiklikleri gidermek içindir. Veri bilimciler için, verilerle çalışmak sıklıkla üç aşamaya ayrılır: verileri temizleme, analiz etme ve modelleme, daha sonra analiz sonuçlarını çizim veya tablo halinde görüntüleme için uygun bir formda düzenleme. Pandas, tüm bu görevler için ideal bir araçtır.
Pandas nasıl kullanılır?
Bu içerik, özellikle yeni kullanıcılar için tasarlanmış Pandas’a giriş niteliğindedir. Daha detaya inmek isterseniz geliştiricilerinin hazırlamış olduğu Cookbook’a göz atabilirsiniz.
Öncelikle eğer bilgisayarımızda Python yüklü ise, Pandas kurulumunu gerçekleştirmek için bilgisayar terminalini açarak aşağıdaki komutu çalıştırmamız gerekiyor.
pip install pandas
Pandas yüklendikten sonra, “En iyi PyCharm Alternatifleri” haberinde bahsettiğimiz herhangi bir Python IDE’sini indirerek aşağıdaki kodu yazarak projemize Pandas kütüphanesini dahil etmiş oluyoruz.
import pandas as pd
Bir tane sözlük oluşturalım.
calisan_listesi= {"isim":["oguzhan","ozgur","yigit","okan","berkay"],
"yas":[22,21,25,20,17],
"maas":[5000,4000,9000,2500,1000]}
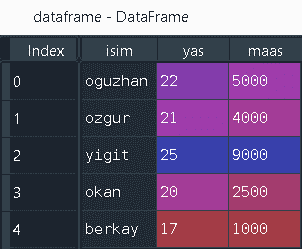
Daha sonra bu sözlüğü Pandas’ın sağlamış olduğu .DataFrame methodu ile DataFrame’e dönüştürüp head() methodu ile ilk 5 satırı yazdırabiliyoruz.
dataframe = pd.DataFrame(calisan_listesi) dataframe.head()
Şu şekilde bir çıktı alıyoruz.
Pandas sütunları columns kullanarak görebiliriz. Info ise içerisinde bulunan verilerin özelliklerini, sütun ve sayısı, boş olup olmadığını, veri tiplerini, ne kadar hafıza kullandığını gösterir.
print(dataframe.columns) #Çıktı: Index(['isim', 'yas', 'maas'], dtype='object') print(dataframe.info()) ''' Çıktı: RangeIndex: 5 entries, 0 to 4 Data columns (total 3 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 isim 5 non-null object 1 yas 5 non-null int64 2 maas 5 non-null int64 dtypes: int64(2), object(1) memory usage: 248.0+ bytes '''
Describe metodu ile nümerik olan veriler analiz edilebilir. Aşağıdaki örnekte görebileceğiniz gibi yaş ve maaş sütunları için minimum, maksimum, medyan, standart sapma gibi değerlere erişebiliriz. İsim String bir veri olduğu için işlem yapılamaz.
print(dataframe.describe())
'''
Çıktı:
yas maas
count 5.000000 5.000000
mean 21.000000 4300.000000
std 2.915476 3033.150178
min 17.000000 1000.000000
25% 20.000000 2500.000000
50% 21.000000 4000.000000
75% 22.000000 5000.000000
max 25.000000 9000.000000
'''
Son olarak, Dataframe üzerinden filtreleme işlemi yapabiliriz. Mesela aşağıdaki kodda maaşı 4000TL’den yüksek olanları listeliyoruz.
print(dataframe[dataframe['maas']>4000]) #Çıktı : isim yas maas 0 oguzhan 22 5000 2 yigit 25 9000