Microsoft Biyomedikal NLP Modeli Geliştirdi


Teknoloji devi Microsoft, geçtiğimiz günlerde Arxiv.org’da bir makale yayımladı. Microsoft araştırma ekibi belirli bir alana özel ön eğitimli biyomedikal NLP (Doğal Dil İşleme) adını verdiği bir fikri öne sürdü.
Yapay zeka artık yaşamımızın büyük bir parçası olmakta. Araştırma ekibi de yapay zekayı biyomedikal alanında nasıl daha etkili kullanabileceklerini düşünüp bu fikri ortaya attı. Ekip; halka açık, herkes tarafından erişilebilir olan açık veri setlerinden kapsamlı bir biyomedikal NLP karşılaştırması derleyerek son teknoloji bir sonuç elde etti. Geliştirilen NLP modeli, adlandırılmış varlık tanıma, raporlardan medikal sonuç çıkarma, döküman sınıflandırma gibi birçok görevi yerine getirebilmekte.
Daha önceki çalışmalar, biyomedikal gibi özel bir alanda alana özgü veri setlerinin NLP modellerinin doğruluğunu artırdığını açıkça göstermişti. Fakat Microsoft araştırma ekibi, yaptıkları biyomedikal NLP çalışmasında alan dışı veri setlerinin de ne kadar etkili olabileceğini gösterdi. Araştırmacılar kaynak alanın genel metin (online dergi, gazete) ya da hedef alanın özel metin (biyomedikal alanındaki akademik makaleler) olduğu “karma alanların” bir transfer learning (transfer öğrenimi) formu olduğunu iddia etmekteler. Buna dayanarak biyomedikal bir NLP modelinin alana özgü ön eğitiminin genel dil modellerinin ön eğitiminden daha iyi performans gösterdiğini ve karma alanlı ön eğitimin her zaman doğru yaklaşım olmadığını gösterdiler.
Microsoft Ekibi Diğer Biyomedikal NLP Modellerini Karşılaştırdı
Araştırma ekibi çalışmalarını kolaylaştırmak adına biyomedikal NLP uygulamaları arasında karşılaştırmalar yaptı. İlk adım olarak ekip, PubMed’den temin edilebilen yayınlara odaklanan ve ilişki çıkarma, cümle benzerliği, soru cevaplama, evet-hayır gibi sınıflandırma görevlerini kapsayan Biomedical Language Understanding & Reasoning Benchmark (BLURB) adlı bir kıyaslama ortamı oluşturdu. Sistem bir özet puanı hesaplamak için içerisindeki topluluk görev türüne göre gruplanır ve ayrı ayrı puanlanır. Ardından da hepsinden bir ortalama hesaplanır.
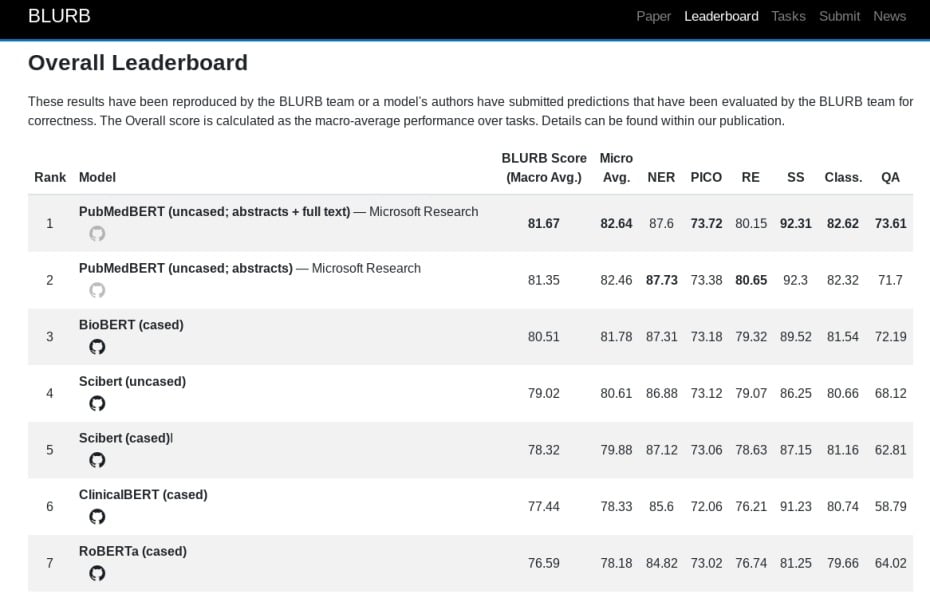
Araştırmacılar; temel biyomedikal modellerle karşılaştırıldığında, Google’ın NLP ön eğitimi için bir tekniği olan BERT temelli inşa edilen modellerinin doğruluk payının daha yüksek olduğunu açıkladı. Özet yerine PubMed’den alınan makalelerin tamamı eğitildiğinde ise (yaklaşık olarak 16.8 milyar kelime) eğitim süresi oldukça uzadı. İlginç bir şekilde ekibin “noise” (gürültü) diye tabir ettiği nedenden dolayı doğruluk oranı azaldı.
Araştırma ekibi, ön eğitim yaklaşımlarını değerlendirmek adına bir kelime dağarcığı oluşturdu ve en son PubMed dökümanları üzerine bir model eğitti. 14 milyon özet içeren veri seti toplamda 3.2 milyar kelime içermekte ve 21 GB boyutunda. Eğitme süreci Nvidia DGX-2 makinesinde yaklaşık olarak 5 gün sürdü.