Makine Öğrenmesi Nedir? - Makine Öğrenmesi Algoritmaları


Çok geniş bir terminolojiye sahip olan yapay zeka, yeni başlayanlarda bazı soru işaretleri oluşturmakta. Daha önceki yazılarımızda yapay zekanın ve derin öğrenmenin ne olduğundan, kullanıldığı alanlardan ve farklarından bahsetmiştik. Bu yazımızda ise makine öğrenmesi nedir konusunu inceleyeceğiz.
Makine Öğrenmesi Nedir?
Yapay zekanın bir alt dalı olan makine öğrenmesi, sistemlere açık şekilde programlanmadan, onun yerine verilen verilerden veya deneyimlerden otomatik olarak öğrenme ve geliştirme yeteneği sağlayan bir disiplindir. Makine öğrenimi, verilere erişebilen ve bunları kendi başlarına öğrenmek için kullanabilen bilgisayar programlarının geliştirilmesine odaklanır.
Bilgisayarlara bu öğrenme yeteneğini kazandırmayı hedefleyen makine öğrenmesinde, istatistiksel ve mantıksal işlemler bunları sağlar. Eğitim verisindeki verileri belirli algoritmalarla öğrenen makine, daha sonra kendi karar verebilecek duruma gelebilir.
Yapay zeka üzerine yapılan çalışmaların artmasıyla, makine öğrenmesi çok sık gündeme gelse de bu fikir 1950’li yıllarda ortaya atıldı. En temel araştırmalar ise 70’li ve 80’li yıllarda yapıldı. Günümüzde ise çok fazla veriye sahip olmamız ve işlem gücünün artması sebebiyle çok fazla ilgi görmekte.
Makine Öğrenmesi Çeşitleri Nedir?
Makine öğrenmesinde amacınıza bağlı olarak makineye verileri öğretebileceğiniz birden fazla yol vardır. Bunlar denetimli (supervised) öğrenme, denetimsiz (unsupervised) öğrenme ve pekiştirmeli (reinforcement) öğrenme olarak sınıflandırılabilir.
Denetimli (Supervised) Öğrenme
Denetimli öğrenmede, makine “etiketli” veriler kullanarak eğitilir. Buradaki etiketi aradığımız sonuç olarak değerlendirebiliriz. Veri setimiz kedi ve köpek görsellerinden oluşuyorsa ve bu verilerin bilgisayara kedi mi yoksa köpek mi olduğu belirtilmişse bu denetimli öğrenme oluyor.
Denetimli öğrenmeyi bir gözetmen ya da denetmen eşliğinde ders çalışılıyormuş gibi düşünebiliriz. Denetimli öğrenmede en önemli kısım modeli eğitmeden önce veriyi ön işlemden güzel ve titiz bir şekilde geçirmektir.
Denetimsiz (Unsupervised) Öğrenme
Denetimsiz öğrenme modeli; denetlemenize gerek olmayan bir makine öğrenmesi tekniğidir. Denetlemenin yerine model kendi başına verilerden anlam çıkarıp, onları sınıflar veya kümeler. Denetimsiz öğrenme esas olarak “etiketsiz” veri ile ilgilenir.
Denetimsiz öğrenme algoritmaları, denetimli öğrenmeye kıyasla daha karışık şeyler oluşturmanıza olanak tanır.
| Denetimli Öğrenme | Denetimsiz Öğrenme |
| Denetimli öğrenmede girdi ve çıktı değişkenleri verilir. | Denetimsiz öğrenmede sadece girdi verileri verilir. |
| Algoritmalar etiketli verilerle eğitilir | Algoritmalar etiketlenmemiş verilerle eğitilir |
| SVM, Yapay Sinir Ağları, Regresyon, Random Forest gibi algoritmalar kullanılır. | Kümeleme, K-Means, Hiyerarşik Kümeleme gibi algoritmalar kullanılır. |
| Daha basittir. | Daha karışıktır. |
| Daha doğru ve güvenilirdir. | Daha az doğru ve öngörülemezdir. |
| Sınıfların sayısı bilinmektedir. | Sınıfların sayısı belli değildir. |
Pekiştirmeli (Reinforcement) Öğrenme
Pekiştirmeli öğrenme, bir dizi karar vermek için makine öğrenmesi modellerinin eğitimidir. Genellikle Agent (Ajan), karmaşık bir ortamda hedefe ulaşmaya çalışır. Pekiştirmeli öğrenmede ajan oyun benzeri bir durumla karşı karşıyadır. Bilgisayar çözüme ulaşmak adına deneme yanılma yöntemini kullanır. Ödül-ceza sistemine sahip olan pekiştirmeli öğrenmede ajan, yaptığı doğru hareketler için ödül alırken yanlışlar içinse ceza yer.
Ajan, bu yediği cezalardan ve aldığı ödüllerden yola çıkarak her denemede kendini daha da geliştirir. Örnek vermek gerekir ise bir modele satranç oynamayı öğretmek istediğinizde ona kuralları öğretmeniz yeterlidir. Ardından model gerek kendi kendiyle oynayarak, gerekse başka bir bilgisayarla oynayarak kendini geliştirir. En başta rastgele hamleler yapacak olan model, ardından bir dünya şampiyonunu yenecek seviyeye gelebilir.
Regresyon ve Sınıflandırma
Regresyon tahmin modelleri aldığı değerle sürekli bir sonuç üretir. Bu sürekli değerler genel olarak miktarlar ve boyutlardır. Örneğin; regresyon tahmin modelleri ile bir evin belirli bir dolar değeri için, belki de 100.000 ila 200.000 dolar aralığında satılacağı tahmin edilebilir.
Sınıflandırma tahmin modelleri ise aldığı değerlerden ayrı çıkış değerleri üretir. Sınıflandırma algoritmaları kategorik verilerde çalışır. Örnek vermek gerekirse bir kişinin boy ve kilosuna göre cinsiyet tahmini yapmak isterseniz bir sınıflandırma modeli oluşturmanız gerekir. Kategorik çıktı değerleri erkek ile kadındır ve model bu iki kategoride verileri öğrenerek ona göre tahminlerde bulunur.
Regresyon Algoritmaları
Simple Linear Regression (Basit Doğrusal Regresyon)
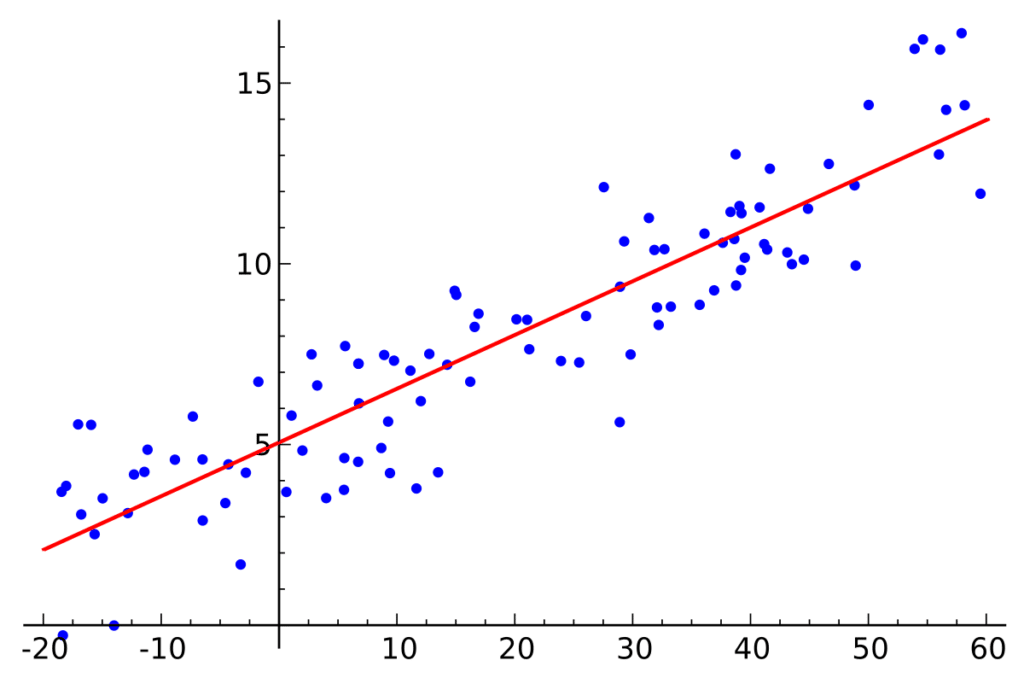
Basit doğrusal regresyon, kullanıcıların iki sürekli değişken arasındaki ilişkileri özetlemesini ve incelemesini sağlayan istatistiksel bir yöntemdir. Doğrusal regresyon, girdi değişkenleri (x) ile tek çıktı değişkeni (y) arasında doğrusal bir ilişki olduğunu varsayan bir modelin bulunduğu doğrusal bir modeldir.
Basit doğrusal regresyon, uygulanabilecek en basit makine öğrenmesi algoritmasıdır. Sadece tek bir x değişkeni olduğundan çok karmaşık bir yapıya sahip değildir. Daha fazla değişken işe dahil olduğunda basit doğrusal regresyon yetersiz kalacağından, polinom regresyonu gibi algoritmalar kullanılabilir.
Lasso Regresyonu
Lasso regresyonu shrinkage (daralma) kullanan bir doğrusal regresyon türüdür. Daralma, veri değerlerinin ortalama gibi merkezi bir noktaya doğru küçüldüğü yerdir. Lasso regresyonu, yüksek düzeyde çoklu doğrusal bağlantı gösterdiğinden, değişken seçimi ve parametre eleme gibi model seçiminin belirli bölümlerini otomatikleştirmek için oldukça uygundur.
Sınıflandırma Algoritmaları
K-Nearest Neighbors (KNN/K-En Yakın Komşu)
K-Nearest Neighbors (KNN) algoritması en çok kullanılan sınıflandırma algoritmalarındandır. Basit, anlaşılır olması ve doğruluk oranı yüksek bir algoritma olduğundan sıklıkla tercih edilmektedir. KNN’de model verilen yeni veriye en yakın olan “K” kadar veriyi inceler (Eğitim veri setindeki). Bu yakınlığı ise öklid ile bulur. Ardından bu en yakın verilerde, hangi kategorinin daha fazla olduğunu bulmak için, yeni eklenen veriyi de o kategori olarak tahmin eder.

Decision Tree (Karar Ağacı)
Decision Tree de KNN gibi kavraması kolay bir algoritmadır. Decision Tree’de algoritma verdiğiniz değeri bir karar ağacına sokar. Örnek vermek gerekirse insanların yaşına ve aktivitesine göre fit olup olmadığının tahminini yapan bir modelde algoritma ilk olarak karar ağacını oluşturur. Aşağıdaki örnekte karar ağacını görebilirsiniz.
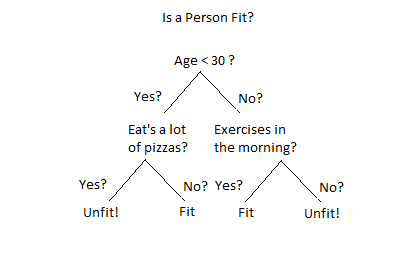
Yukarıdaki karar ağacı üzerinden gidersek model yeni verilen veride ilk olarak şu soruyu sorar “Kişi 30 yaşından büyük mü?”. Eğer büyükse diğer soruya geçer “Sabahları egzersiz yapıyor mu?”. Eğer egzersiz yapıyorsa verilen veriyi “Fit”, yapmıyorsa “Fit değil” olarak etiketler.