Image Segmentation (Görüntü Bölütleme) Nedir?


Daha önce yazmış olduğumuz Nesne Tanıma Algoritmaları yazımızda, makinelerin görseller üzerindeki objeleri nasıl tespit ettiğini ve nasıl çıktılar verdiklerini incelemiştik. Bu nesne tanıma algoritmaları çıktı olarak görselde bulunan objelere ait sınıfları ve objelerin bounding boxlarını (sınırlayıcı kutuları) çıktı olarak vermektedir. Fakat bu bounding boxlar bazı durumlarda bizlerin yeterince işine yaramamakta. En basit örnek üzerinden gitmek gerekirse günümüzde popüleritesi gittikçe artmakta olan otonom araçlarda bu teknolojiler kullanılmakta. Fakat bu araçların, nesnelerin bounding boxlarını tespit etmesi büyük sorunlara yol açmakta. Bu araçların nesneleri kapsayan kutular yerine tam olarak nesnelerin sınırlarını tespit etmesi gerekmekte. Bu sorun için kullanılan Image Segmentation yani görüntü bölütleme nedir?
Image Segmentation görselde bulunan objelerin sınıflarının yanı sıra bounding boxlardan ziyade sınırlarının maskelerle belirtilmesi için kullanılır. Temel olarak iki farklı bölütleme tekniği vardır. Bunlar Semantic Segmentation ve Instance Segmatationdır.
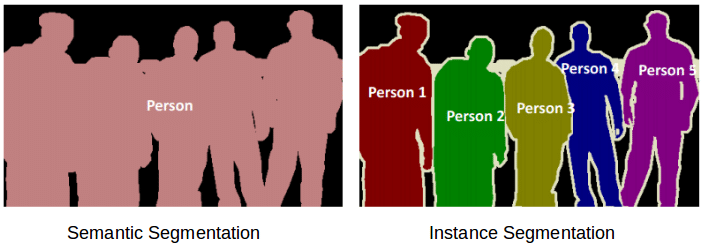
Semantic Segmentation: Semantic Segmentation, bir görüntüde bulunan tüm objeleri piksel düzeyinde algılar ve farklı sınıflara ait nesnelere sahip bölgeleri çıkarır. Görseldeki tüm objeleri ayrı ayrı gruplar.
Instance Segmentation: Instance Segmentation’da her piksele belirli bir sınıf atanır fakat, aynı sınıftaki iki farklı nesne birbirlerinden farklı renklere sahiptir.
Klasik Image Segmentation Yöntemleri Nedir?
Threshold (Eşik Değer) Segmentation
Bilindiği üzere aslında kullandığımız görseller RGB (Red-Green-Blue) olmak üzere 3 katmandan oluşan, piksel değerlerine sahip olan matrislerdir. Eğer bunları gray-scale yani tek katmanlı siyah beyaz, renksiz bir hale getirirsek 3 katmandan kurtulmuş oluruz. Tek katmanlı bu görselde nesneler arası geçişler ve arka plandan bağımsız nesneler farklı piksel değerlerine sahip olduğundan bir threshold (eşik) değer belirleyerek resimdeki görselleri ayırabiliriz.
Genelde kullanılan iki farklı threshold değeri vardır:
- Global Threshold: Görüntüyü sadece nesne ve arkaplan olarak ikiye bölmek için kullanılır. Tek bir eşik değer belirlenir ve bu değer global thresholddur.
- Local Threshold: Arka plandan birden fazla nesneyi ayırmak için tek bir threshold değeri yerine birden fazla threshold değeri belirlenir. Bu değerlerin hepsi bir local thresholddur.
Basit bir şekilde global threshold üzerinden gidersek görselde değer belirlemek için farklı teknikler kullanabiliriz. Pek verimli olmasa da bu değeri rastgele de seçebiliriz. Fakat genellikle eşik değer seçiminde ortalama piksel değeri kullanılmaktadır. Ardından görseldeki tüm değerler bu eşik değeri ile karşılaştırır ve yüksek olanlar siyah düşük olanlar da beyaz olarak atanır.

Kümeleme ile Segmentasyon
Kümeleme tekniği makine öğrenmesinde gözetimsiz öğrenmede sıkça kullanılan bir yöntemdir. Sınıflandırma problemlerinde etiketsiz veriyi belirli niteliklere göre kendi başına sınıflandıran kümeleme algoritmaları görüntü bölütlemede de kullanılmaktadır.
Bunun için çok sık kullanılan K-Means algoritmasını kullanabiliriz. K-Means algoritması görseli girdi olarak alır ve görseldeki pikselleri elde edilmek istenen sınıf kadar gruplar. Kümeleme algoritmasının temelinde model ilk olarak rastgele küme merkezleri belirler ve o bölgeye yakın olan değerleri renklerle belirler. Ardından bu kümelerin merkezlerini hesaplar ve yeni kümeleri belirler. Bu işlemi iteratif olarak merkezler değişmeyinceye kadar yapar ve merkezler artık değişmediğinde kümeler son halini almış olur.

Kümele ile sınıflandırma yapmak basit ve kullanışlı olsa da eğitim süreci ve kümelerin belirlenmesi uzun sürebilmekte. O nedenle çok fazla tercih edilen bir yöntem değildir.
Derin Öğrenme ile Image Segmentation
Mask R-CNN
Image Segmentation’da objeleri doğru şekilde belirlemek kadar bunları anlık hızlı bir şekilde yapmak da oldukça önemlidir. Genellikle klasik teknikler hem doğruluk hem de performans açısından yeterince güzel sonuçlar vermediğinden bu konuda da sinir ağlarından yardım alındı. Facebook AI ekibinde yer alan araştırmacılar her nesne için maske oluşturabilen Mask R-CNN mimarisini geliştirdi. Mask R-CNN popüler olan ve Nesne Tanıma Algoritmaları yazımızda bahsettiğimiz Faster R-CNN’in bir uzantısıdır.
Faster R-CNN görüntüdeki her obje için iki farklı çıktı üretir. Bunlardan biri objenin ait olduğu sınıf diğeri ise objenin sınırlayıcı kutusudur. Mask R-CNN ise bu çıktılara ek olarak üçüncü bir dal üretir. Bu ekstra çıktı objeleri kapsayan maskelerdir.
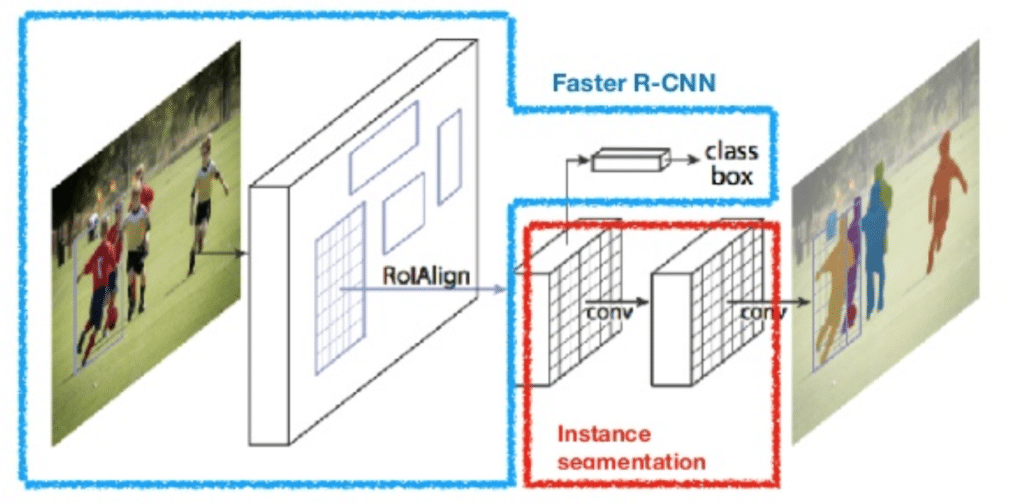
Mask R-CNN:
- Bir görüntüyü girdi olarak alır ve öznitelik haritalarını çıkarması için CNN ağına aktarır.
- Region Proposal Network (RPN) ile bu öznitelik haritalarından objelik skoruna göre bölge önerileri üretir.
- Tüm öneri bölgeleri aynı boyuta getirmek için bu bölgelere bir ROI havuz katmanı uygulanır.
- Ardından Fully Connected Layer’da istenilen çıktılar alınır.
Mask R-CNN, image segmentation için kullanılan en güçlü mimarilerden biridir. 5 FPS yani saniyede 5 kare için tahminlemede bulunabilir.
Temel olarak Image Segmentation nedir ve nasıl çalışır sorularını cevaplamaya çalıştık. Mask R-CNN ile ilgili kod parçacıklarına ve gerekli bilgilere bu github reposundan ulaşabilirsiniz.