Doğrusal Regresyon: Teori ve Python ile Uygulanması


Makine öğrenimi eğitimlerine başlayan herkes ilk olarak doğrusal regresyon ile tanışır. Makine öğrenimi algoritmalarının temel mantığını sağlam bir şekilde kavrama konusunda doğrusal regresyon önemli bir yere sahiptir. Makine öğrenimine giriş yapmak için doğrusal regresyonun teorik ve uygulama kısımlarını anlaşılır bir şekilde ele alacağız.
Teori
Doğrusal Regresyonun temel amacı modeldeki bağımlı ve bağımsız değişken arasındaki ilişkiyi açıklayan doğrusal fonksiyonu bulmaktır.

Formülde görmüş olduğunuz Yİ ifadesi bize bağımlı değişkeni ifade eder. Bazı kaynaklarda hedef değişken olarak da görebileceğiniz bu ifadede X ile temsil edilen bağımsız değişkenlerin katsayılarla çarpılması sonucu bir değere ulaşmaya çalışırız.
B0 ifadesi bize sabit katsayıyı verir. Basit Doğrusal Regresyonda tek bir bağımsız değişken üzerinden hesaplama yaptığımız için B1 elimizdeki bağımsız değişkenin önündeki katsayıyı temsil eder.
ε ifadesi ise gerçek veri ile tahmin edilen verinin arasındaki farkın temsilcisidir.
Peki, makine öğrenimi modeli kurulurken üzerinde çok durulan bu fark ne anlama geliyor?
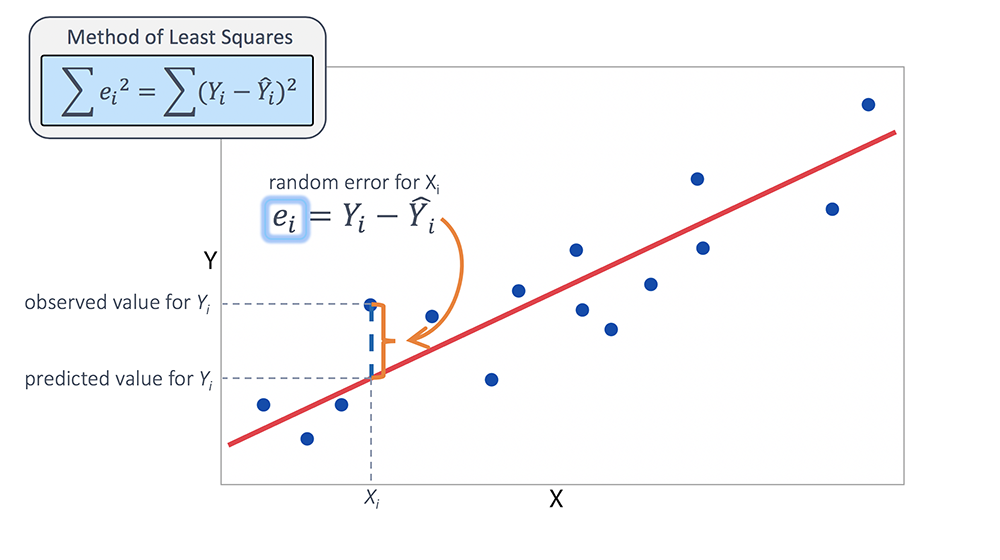
Görmüş olduğunuz modelde birbirine yakın şekilde dağılmış mavi noktalar gerçek değerleri göstermektedir. Doğrusal çizilmiş kırmızı çizgi ise tahminci fonksiyonumuzdur. Gerçek değeri gösteren mavi nokta ile tahmin çizgisinin arasında kalan mesafeyi modeldeki fark veya hata olarak değerlendiriyoruz ve makine öğrenimi algoritmalarında bu değeri mümkün olduğunca minimize etmeye çalışıyoruz.
Python ile Doğrusal Regresyon
Temel teorik kavramları tanıttıktan sonra Python dilinde scikit-learn kütüphanesini kullanarak bir basit doğrusal regresyon algoritmasını uygulayacağız.
Öncelikle şu adrese gidip Advertising adlı veri setini çalışmak istediğimiz dizine indirmemiz gerekiyor. Bu veri setinde tv, radyo ve gazetelere verilen reklamların satışlara olan etkisini inceleyeceğiz. Temel veri manipülasyonları için pandas kütüphanesini yüklüyoruz.
import pandas as pd
ad = pd.read_csv("Advertising.csv", usecols = [1,2,3,4])
df = ad.copy()
df.head()pd.read_csv koduyla veri setimizi içeri aktardık ve usecols argümanı ile sütun isimlendirmesi yaptık. df.head fonksiyonu ile ilk değerlere bir bakış atıyoruz. Çıktımız aşağıdaki gibidir.
| TV | radio | newspaper | sales | |
|---|---|---|---|---|
| 0 | 230.1 | 37.8 | 69.2 | 22.1 |
| 1 | 44.5 | 39.3 | 45.1 | 10.4 |
| 2 | 17.2 | 45.9 | 69.3 | 9.3 |
| 3 | 151.5 | 41.3 | 58.5 | 18.5 |
| 4 | 180.8 | 10.8 | 58.4 | 12.9 |
df.info() ile veri seti hakkında biraz bilgi edinelim. Bu kodu çalıştırınca veri setinde 200 gözlem 4 değişken olduğunu ve veri tipinin float64 olduğunu görebilirsiniz.
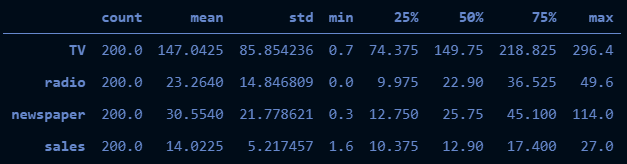
df.describe().T fonksiyonu ile transpozu alınmış bir şekilde istatistik tablosunu elde edip standart sapma, çeyreklikler, minimum ve maksimum değerler gibi betimlemelere aşağıdaki gibi göz atabiliriz.
df.isnull().values.any() fonksiyonu ile veri setinde eksik değer olup olmadığını sorguluyoruz ve False ifadesi ile hiçbir değerin eksik olmadığına ulaşıyoruz.
df.corr() fonksiyonu ile değişkenlerin kendi içlerindeki korelasyonları inceleyebiliyoruz.
| TV | radio | newspaper | sales | |
|---|---|---|---|---|
| TV | 1.000000 | 0.054809 | 0.056648 | 0.782224 |
| radio | 0.054809 | 1.000000 | 0.354104 | 0.576223 |
| newspaper | 0.056648 | 0.354104 | 1.000000 | 0.228299 |
| sales | 0.782224 | 0.576223 | 0.228299 | 1.000000 |
TV ile sales değişkenleri arasındaki yüksek korelasyona bakınca tv için yapılan reklam harcamalarındaki bir birimlik artışın satışlarda 0.78 birimlik bir yükselişe denk geldiğini görebiliyoruz.
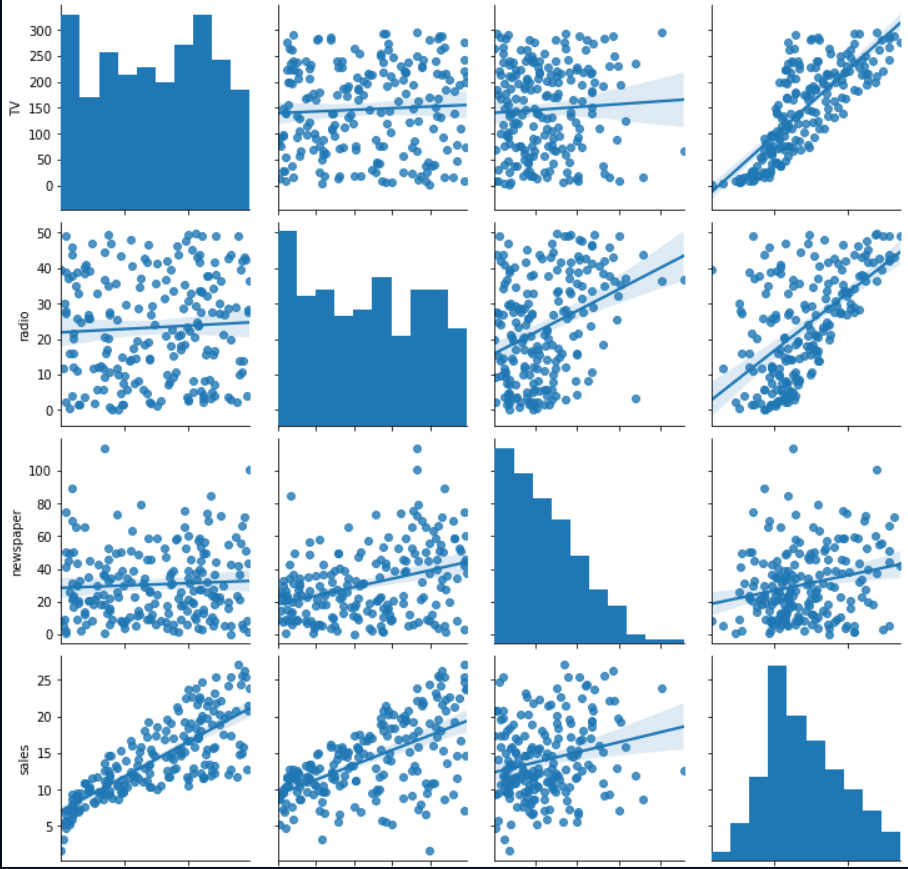
Eğer bu korelasyonları görsel olarak incelemek istiyorsak bunun için seaborn kütüphanesindeki pairplot fonksiyonu yardımımıza koşuyor. Aşağıdaki kodu çalıştırdığımızda detaylı bir görsel incelemesi yapabiliriz.
import seaborn as sns
sns.pairplot(df, kind ="reg");
Model Kurma
Veri setine hızlıca bir göz attıktan sonra şimdi scikit-learn ile modeli kuracağız.
from sklearn.linear_model import LinearRegression kodu ile scikit-learn kütüphanesinden doğrusal regresyon fonksiyonunu çağırıyoruz.
Paket yüklendikten sonra aşağıdaki kodları yazıyoruz.
X = df[["TV"]]
y = df["sales"]
reg = LinearRegression()
model = reg.fit(X, y)
model.intercept_
model.coef_Yukarıda X değişkenine TV değerlerini, Y değişkenine satış değerlerini atadık. reg ifadesine fonksiyonu atayıp bir nesne oluşturduk ve bu nesne üzerinden fit() fonkiyonu ile modeli kurduk. Intercept ve coef fonksiyonları ile formüldeki B0 ve B1 katsayılarını çağırıyoruz. Ayrı ayrı çalıştırınca Intercept değerinin 7.032, coef değerinin ise 0.047 olduğunu gözlemlemekteyiz.
Predict adlı fonksiyon ile tahmin çalışmalarımızı gerçekleştiriyoruz. Bunun bir örneğini görmek için aşağıdaki kodu editörümüze yazalım.
model.predict(X)[0:10]array([17.97077451, 9.14797405, 7.85022376, 14.23439457, 15.62721814,
7.44616232, 9.76595037, 12.74649773, 7.44140866, 16.53041431])Yukarıda, algoritmadan veri setinin ilk 10 değerini tahmin etmesini istedik ve bir dizi halinde bize satış değerlerini yazdırdı.
Intercept ve coef fonksiyonlarını çalıştırıp elde ettiğimiz çıktılara göre modelin denklemini
Sales = 7.03 + TV*0.04
şeklinde yazabiliriz.
İncelemenin sonlarına doğru model üzerinden bir örnek gerçekleştirelim. TV için reklam harcamalarına 50 birim para miktarı ayrılıyor ve bu sonuçlara göre bizden satışlardaki artışın kaç birim olacağı soruluyor. Bunun için model.predict([[50]]) adlı kodu yazıyoruz ve çıktı olarak array([9.40942557]) ifadesini elde ediyoruz. Yani 50 birimlik bir tv harcamasına karşılık satışlarda elde edeceğimiz değer 9.41 birim oluyor.
Bu yazıda temel hatlarıyla Python dilinde doğrusal regresyonun nasıl çalışacağı üzerinde durduk. Sorularınızı ve görüşlerinizi yorumlarda belirtebilirsiniz.