Bilgisayar Dosya Sıkıştırma İşlemini Nasıl Yapar?


Günümüzde teknolojinin hayatımızda daha da fazla yer edinmesi ile kullanıcıların tükettiği veri miktarı gittikçe artmaktadır. Dosya boyutları da bu gelişime paralel bir büyüme sergilemekte. Artık çektiğimiz fotoğraflar ve videolar daha fazla kaliteli olduğundan kapladıkları yer de gittikçe artmakta. Tabi ki de bilgisayar bilimcileri bu sorun için de geçici bir çözüm bulmuş durumda. Bu teknoloji uzun zamandır hayatımızın parçası olan “Sıkıştırma” teknolojisi. Sıkıştırma teknolojisi, sıkıştırma algoritmaları ile elimizdeki büyük boyutlarda ki dosyaları daha küçük boyutlara indirgeyerek daha az yer kaplamalarını sağlar.
Kullandığımız dosyaları sıkıştırmak için WinRAR, WinZip gibi uygulamalar kullanmaktayız. Peki bu uygulamalar neye göre bu dosyaların boyutunu küçültmekte? Öncelikle şunu bilmeliyiz ki metin sıkıştırma işlemi resim ve video sıkıştırmaya göre daha farklıdır. Resim ve videolarda dosyaları sıkıştırdığınızda veri kaybı yaşarsınız. Yani resmin sıkıştırdığınız hali aslına göre daha az detay içerir. Fakat metin sıkıştırma tamamen kayıpsız olur. Zaten anlam karmaşası olmaması için metin sıkıştırırken bilgi kaybetmememiz gerekir.
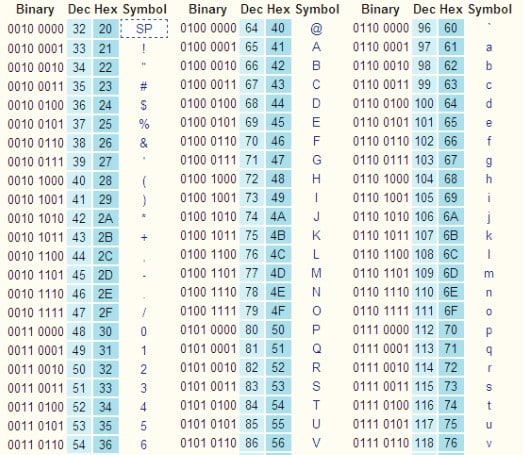
Bir metin oluşturduğunuzda her karakter 8 bit’lik yani 8 hanelik 1 ve 0’lar şekilde bilgisayarda tutulur. Bu da bize 2 üzeri 8 yani 256 farklı karakter saklama imkanı verir. Bu karakterler büyük harf, küçük harf, noktalama işaretleri, hatta bizim alfabemizde bulunan ç, ü, ğ, ı, ş gibi özel karakterleri içermektedir. Peki neden 8? Çünkü 8 hane tüm karakterleri saklamak için şimdilik bizim için yeterli.
Huffman Coding
1949 yılında Claude Shannon ve Robert Fano, Shannon-Fano Kodlamasını keşfettiler. Sıkıştırma algoritması olan bu yöntem pek optimum düzeyde olmasa da birikimli dağılım fonksiyonu ile karakterlerin olasılıklarına göre belirli bir düzeyde dosyaları sıkıştırıyordu.
1952 yılına gelindiğinde ise David Albert Huffman doktora döneminde bir entropi kodlama uygulaması olan Huffman Kodlamasını geliştirdi. Huffman Kodlaması Shannon-Fano’ya göre çok daha optimize edilmiş biçimdeydi ayrıca dosyaları sıkıştırma oranı daha da yüksekti.
Huffman Kodlamasını Nasıl Yapabiliriz?
Huffman Kodlaması ile dosyalarınızı sıkıştırmak için ilk olarak verilen metinde her karakterin ne kadar geçtiğini bulun (yani frekanslarını) ve bunları büyükten küçüğe sıralı bir şekilde listeleyin. Ardından listenizin en alt sıradaki 2 elemanını alın. Bu iki eleman oluşturacağımız Huffman Ağacının yaprakları, yani en alt elemanları olacak. Ardından bu 2 elemanı birbirine bağlayın ve bağlayacı node’un değerine 2 elemanın frekansları(en başta hesapladığımız metinde kaç kere geçtikleri) toplamını yazın. Ardından aşağıdan devam ederek her elemanı bu ağacınıza ekleyin ve karşınıza büyük bir Huffman ağacı çıkacak.
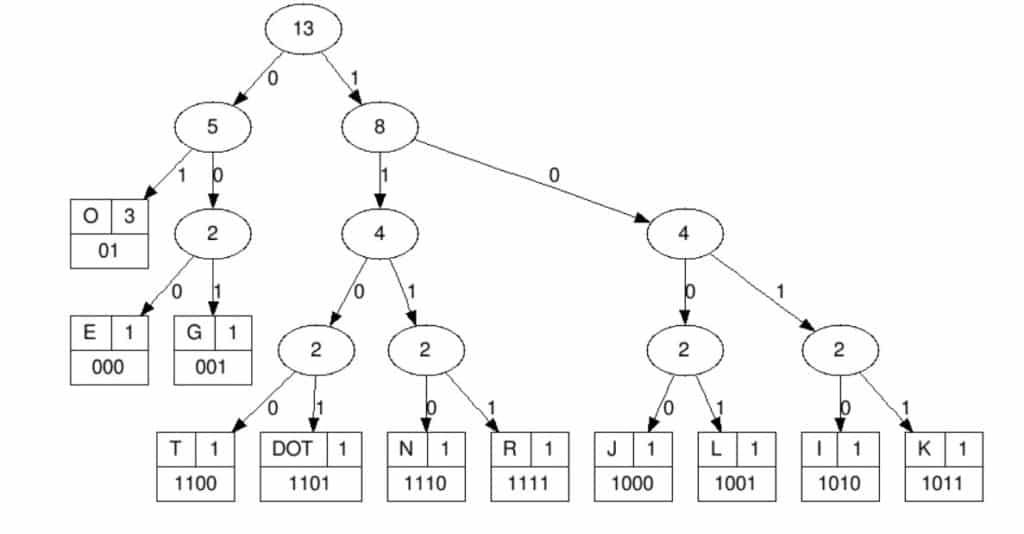
Şimdi sıra metnimizi sıkıştırmaya geldi. Sıkıştırmak istediğiniz metnin “teknoloji.org” olduğunu varsayalım. Huffman ağacımızı oluşturduktan sonra ilk sıkıştıracağımız karakter “t” harfi. Bu harfin ağacımızda ki yerini belirliyoruz ve başlangıç noktasından o harfin olduğu node’a gitmeye çalışıyoruz. Gittiğimiz süreçte her sağ’a geçişimizde 1, her sola geçişimizde 0 yazıyoruz. Hedeflediğimiz node’a vardığımızda artık “t” harfinin yeni değeri birleştirdiğimiz 0 ve 1 ler oluyor.
Bazen bu kodlama sonucunda elde ettiğimiz yeni karakterin bit sayısı 8 biti geçebiliyor fakat bu karakterler ağacın en altında bulunduğundan dolayı az tekrar eden karakterler oluyor. Yani daha sıklıkla tekrar eden karakterler ağacın üst kısımlarında kaldığından onlar sıkıştırma yüzdemizi her seferinde daha da arttırıyor. Ayrıca bu Huffman kodlaması “teknoloji.org” gibi fazla bit içermeyen metinler için pek kârlı bir method değildir.
Eğer siz de kendi Huffman Ağacınızı oluşturup metninizi sıkıştırmak isterseniz bu siteden kendi Ağacınızı oluşturup metin sıkıştırmasını deneyebilirsiniz.