Apache Spark Nedir? Nasıl Çalışır?


Apache Spark, büyük ölçekli veri analizi uygulamalarını çalıştırmak için kullanılan açık kaynaklı bir paralel işleme çerçevesidir.
Apache Spark’ın 1.0 sürümü Mayıs 2014’te yayınlandı ve o günden beri en çok tercih edilen veri işleme motoru oldu.
Bu teknoloji ilk olarak 2009 yılında California Üniversitesi’ndeki araştırmacılar tarafından Hadoop sistemlerindeki işlemleri hızlandırmak için tasarlandı.

Projenin kalbi olan Spark Core; Hadoop’un bağlı olduğu MapReduce’a potansiyel olarak daha hızlı ve daha esnek bir alternatif olarak tasarlanmıştır. En çok tercih edilen Spark’ın, MapReduce’dan 100 kat daha hızlı çalıştığı iddia edilmektedir. Spark ve MapReduce arasındaki temel fark, Spark’ın verileri sonraki adımlar için işlemesi ve bellekte tutmasıdır, bu da önemli ölçüde daha hızlı işlem yapılmasına olanak sağlar.
Apache Spark Nedir?
Apache Spark, büyük veri kümelerindeki görevleri hızlı bir şekilde gerçekleştirebilen, aynı zamanda veri işleme görevlerini birden çok bilgisayara tek başına dağıtabilen veya diğer dağıtılmış bilgi işlem araçlarıyla birlikte dağıtabilen bir veri işleme motorudur. Bu iki nitelik, Büyük Veri depoları arasında hızla ilerlemek için gerekli olan bilgi işlem gücünün düzenlenmesini sağlayan büyük veri ve makine öğrenimi dünyalarının anahtarıdır.
Spark, Java, Scala, Python ve R programlama dilleri için yerel bağlantılar sağlayabilir ve SQL, veri akışı, makine öğrenimi ve grafik işleme gibi işlemleri destekler. Bankalar, telekomünikasyon şirketleri, oyun şirketlerinin yanı sıra, Apple, Facebook, IBM ve Microsoft gibi büyük teknoloji devleri tarafından da kullanılmaktadır.
Apache Spark nasıl çalışır?
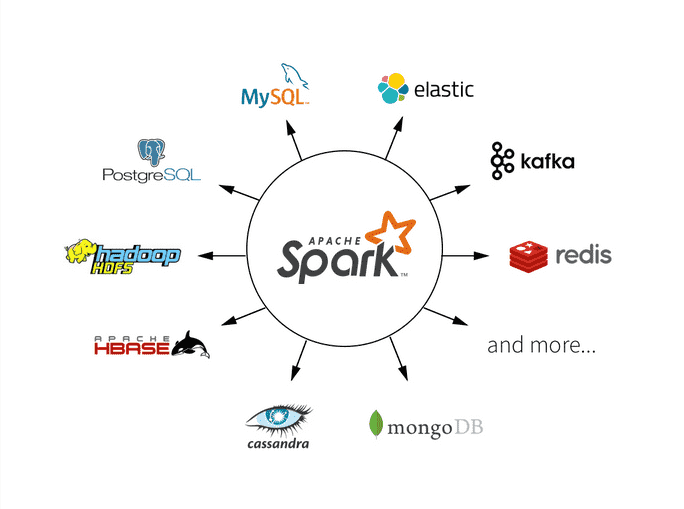
Apache Spark, Hadoop Dağıtılmış Dosya Sistemi (HDFS), NoSQL veritabanları ve Apache Hive gibi çeşitli veri havuzlarındaki verileri işler. Spark, büyük veri analizi uygulamalarının performansını artırmak için bellek içi işlemeyi desteklemektedir. Ancak, veri kümeleri mevcut sistem belleğine sığamayacak kadar büyük olduğunda disk tabanlı işlemeyi de gerçekleştirebilir.
Apache Spark, hiyerarşik bir mimariye sahiptir. Spark sürücüsü, çalışan düğümleri yöneten ve küme yöneticisini kontrol eden ana düğümdür.
Spark Core motoru, temel veri türü olarak esnek dağıtılmış veri kümelerini (RDD) kullanmaktadır. RDD, hesaplama karmaşıklığını kullanıcılardan gizleyecek şekilde tasarlanmış bir yapıya sahiptir. Spark Core motoru, verileri toplar ve daha sonra hesaplanabileceği farklı bir veri deposuna taşır. Sonrasında analitik model üzerinden çalıştırılabileceği bir sunucu kümesine böler. Kullanıcının, belirli dosyaların nereye gönderileceğini, dosyaları depolamak veya almak için hangi hesaplama kaynaklarının kullanılacağını tanımlaması gerekli değildir.
Esnek Dağıtılmış Veri Kümesi (RDD)
Esnek Dağıtılmış Veri Kümeleri (RDD), kümelerdeki birden çok düğüm arasında dağıtılabilen ve paralel olarak üzerinde çalışılabilen, hataya dayanıklı öğe koleksiyonlarıdır. RDD’ler, Apache Spark’ın temel bir yapısıdır.
Spark, mevcut bir koleksiyonu SparkContext paralelleştirme yöntemiyle işlemek için bir RDD’ye paralelleştirerek verileri yükler. Veriler bir RDD’ye yüklendikten sonra, bellekteki RDD’ler üzerinde dönüşümler ve eylemler gerçekleştirir. Spark ayrıca, sistem hafızası bitmedikçe veya kullanıcı verileri kalıcılığı sağlamak için diske yazmaya karar vermedikçe verileri bellekte depolar.
RDD’deki her veri kümesi, kümenin farklı düğümlerinde hesaplanabilen mantıksal bölümlere bölünmüştür. Kullanıcılar iki tür RDD işlemi gerçekleştirebilir: dönüşümler ve eylemler. Dönüşümler, yeni bir RDD oluşturmak için uygulanan işlemlerdir. Eylemler, Apache Spark’a hesaplama uygulaması ve sonucu sürücüye geri gönderme talimatını vermek için kullanılır.
Apache Spark Mimarisi
Apache Spark uygulaması iki ana bileşenden oluşur. İlk bileşen kullanıcının kodunu düğümler arasında dağıtıp birden çok göreve dönüştüren bir sürücüdür. Diğer bileşen ise bu düğümlerde atanan görevleri yürüten yürütücülerdir. İkisi arasında arabuluculuk yapmak için bir tür küme yöneticisi gerekmektedir.
Spark, kümenizdeki her makinede Apache Spark çerçevesi ve bir JVM (Java Virtual Machine) gerektiren bağımsız bir küme modunda çalışabilir. Hadoop YARN; daha sağlam bir kaynak veya küme yönetim sisteminden yararlanmak anlamına gelir. Buna ek olarak Apache Spark, Apache Mesos, Kubernetes ve Docker Swarm üzerinde de çalışabilir.
Apache Spark, kullanıcıların veri işleme komutlarını Directed Acyclic Graph (DAG) olarak oluşturur. DAG, Apache Spark’ın zamanlama katmanıdır, görevlerin hangi düğümlerde ve hangi sırayla yürütüleceğini belirler.
Spark Kütüphaneleri
Spark Core, kısmen bir uygulama programlama arabirimi (API) katmanı olarak işlev görür. Spark Core işleme motorunun yanı sıra Apache Spark API ortamı, veri analitiği uygulamalarında kullanılmak üzere bazı kod kütüphaneleriyle birlikte gelir. Bu kütüphaneler;
Spark SQL – En yaygın kullanılan kütüphenelerden biri olan Spark SQL, kullanıcıların ortak SQL dilini kullanarak farklı uygulamalarda depolanan verileri sorgulamasını sağlar.
Spark Streaming – Verileri gerçek zamanlı olarak analiz eden ve sunan uygulamalar oluşturmasına olanak tanıyan bir kütüphanedir.
MLlib – Kullanıcıların Spark kümelerindeki verilere gelişmiş istatistiksel işlemler uygulamasına ve bu analizler etrafında uygulamalar oluşturmasına olanak tanıyan bir makine öğrenimi kodu kütüphanesidir.
GraphX – Grafik paralel hesaplama için yerleşik bir algoritma kütüphanesidir.
Spark SQL
Spark SQL, Apache Spark projesi için gittikçe daha önemli hale gelmektedir. Geliştiricilerinin uygulama oluştururken en yaygın olarak kullandıkları arayüzlerden bir tanesidir. Spark SQL, R ve Python’dan (Pandas) ödünç alınan bir veri çerçevesi yaklaşımı kullanarak yapılandırılmış verilerin işlenmesine odaklanmıştır. Spark SQL aynı zamanda verileri sorgulamak için SQL2003 uyumlu bir arayüz sağlayarak Apache Spark’ın gücünü geliştiricilerin yanı sıra analistlere de sunmaktadır.
Apache Spark ve Makine Öğrenimi
Spark, makine öğrenimi, yapay zeka (AI) ve akış işleme için çeşitli kütüphanelere sahiptir.
Spark Streaming
Spark Streaming, canlı veri akışlarının ölçeklenebilir, hataya dayanıklı bir şekilde işlenmesini sağlayan temel Spark API’nin bir uzantısıdır. Spark Streaming verileri işlerken, Spark’ın makine öğrenimi ve grafik işleme algoritmalarıyla gerçek zamanlı akış analitiği için verileri dosya sistemlerine, veritabanlarına ve canlı panolara iletebilir. Spark SQL motoru üzerine kurulu olan Spark Streaming ayrıca, akışlı verilerin daha hızlı işlenmesiyle sonuçlanan toplu işlemeye izin verir.
Apache Spark MLlib
Apache Spark’ın kritik yeteneklerinden biri, Spark MLlib’de bulunan makine öğrenimi yetenekleridir. Apache Spark MLlib, sınıflandırma ve regresyon, işbirliğine dayalı filtreleme, kümeleme, dağıtılmış doğrusal cebir, karar ağaçları, sık model madenciliği, değerlendirme ölçümleri ve istatistikler yapmak için kullanıma hazır bir çözüm sunar. MLlib’in çeşitli veri türleriyle bir araya gelen yetenekleri, Apache Spark’ı vazgeçilmez bir büyük veri aracı haline getirir.
Spark GraphX
Spark GraphX: API’a sahip olmanın yanı sıra, Spark’ın grafik sorunlarını çözmek için tasarlanmış yeni bir eklentidir. GraphX, grafikler ve grafik-paralel hesaplama için RDD’leri genişleten bir grafik soyutlamasıdır. Spark GraphX, sosyal ağlar gibi ara bağlantı bilgilerini veya bağlantı bilgileri ağlarını depolayan grafik veri tabanlarıyla entegre olur.
Apache Spark Kullanım Örnekleri
Dijital reklam şirketleri Spark’ı, web sitelerinin veri tabanlarını korumak ve belirli tüketicilere özel kampanyalar tasarlamak için kullanır. Finans şirketleri, finansal verileri almak ve yatırım faaliyetlerine rehberlik etmek için kullanır. Tüketici ürünleri şirketleri, envanter kararlarına rehberlik etmek ve yeni pazar fırsatlarını tespit etmek, müşteri verilerini toplamak ve trendleri tahmin etmek için kullanır.
Büyük veri uygulamalarıyla çalışan büyük kuruluşlar, hızı ve birden çok veri tabanını birbirine bağlama ve farklı türlerde analitik uygulamaları çalıştırma yeteneği nedeniyle Spark kullanmaktadır.