TPOT Nedir? Nasıl Kullanılır? - Python Kütüphanesi


Bu yazımızda, Python’ın eşsiz bir kütüphanesi olan TPOT kütüphanesi nedir ve nasıl kullanılır, öğreniyor olacağız. Peki bu kütüphaneyi eşsiz yapan şey , bütün makine öğrenmesi hattını otomatikleştirmesi ve en iyi performansı sağlayan makine öğrenmesi modelini sunmasıdır. Daha spesifik olursak şunları öğreneceğiz:
- Otomatize edilmiş makine öğrenmesi fikrinin arka planı
- TPOT, en iyi makine öğrenme modelini seçmek için Genetik Algoritmayı nasıl kullanır?
- Python’da veri seti üzerinde TPOT kullanımı
- TPOT’un limitleri
O zaman başlayalım!
Giriş
Bir makine öğrenmesi problemi çözmeden önce veri hazırlama, öznitelik seçimi, model seçimi ve çapraz geçerlilik, hiper parametre ayarı gibi halledilmesi gereken bir çok bileşen var. Teorik olarak, bu bileşenlerin her biri için çok sayıda teknik bulabilir ve uygulayabilirsiniz. Ancak bu teknikler her veri seti için farklılık gösterebilir. Buradaki zorlu kısım tahminlerinizdeki hatayı en aza indirmek için en iyi performans gösteren teknikleri bulmaktır. Son zamanlarda insanların Auto-ML algoritmaları ve platformları geliştirmek için çalışmasının asıl sebebi budur. Böylece makine öğrenimi hakkında çok fazla tecrübesi olmayan herkes inanılmaz zaman harcamadan bir makine öğrenmesi modeli oluşturabilir. Python kütüphanesi olarak böyle bir platform mevcuttur: TPOT. Aslında TPOT’u veri bilimi asistanınız olarak düşünebilirsiniz. TPOT, genetik programlama kullanarak makine öğrenme hattını optimize eden bir Otomatikleştirilen Makine Öğrenmesi aracıdır. Verileriniz için en iyi sonucu elde etmek için binlerce olası hatları keşfederek makine öğreniminin en sıkıcı kısmını sizin için otomatikleştirecektir.
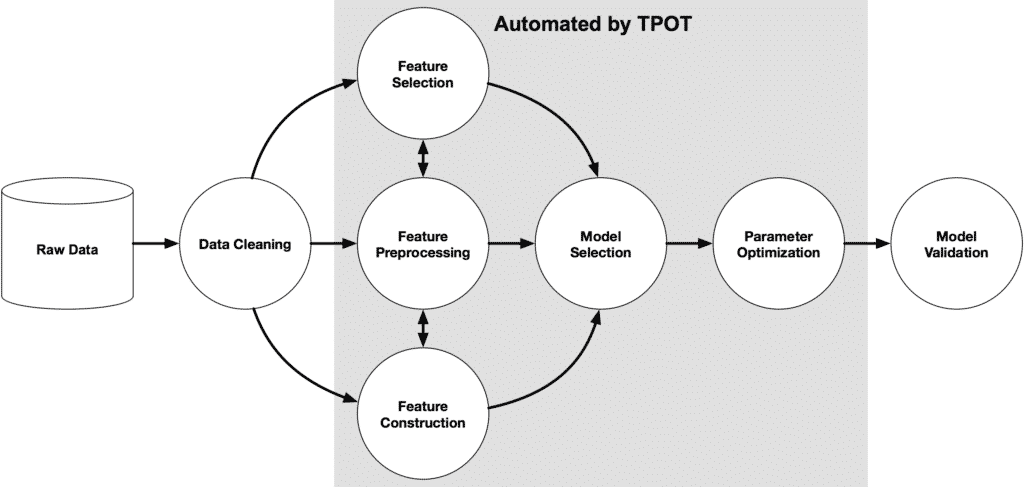
TPOT aramayı bitirdiğinde, bulduğu en iyi hattı size Python kodu olarak döndürür. Böyle oradan hattı istediğiniz gibi düzenleyebilirsiniz.
Kurulum
TPOT’u sisteminize yüklemek için, komut satırında şu kodu çalıştırmalısınız:
sudo pip install tpot
Numpy, scipy, scikit-learn, DEAP, update_checker, tqdm, stopit ve pandas dahil olmak üzere birçok Python kütüphanesinin üstüne kurulmuştur. Gerekli Python paketlerinin çoğu Anaconda Python dağıtımı ile kurulabilir veya ayrı olarak da kurabilirsiniz. İsteğe bağlı olarak, tpot’un eXtreme Gradient Boosting modellerini kullanmasını da istiyorsanız XGBoost’u da yükleyebilirsiniz.
Genetik Programlama
Eğer elinizde düzgün veri, yeterli bilgi işlem gücü ve makine öğrenimi var ise herhangi bir soruna çözüm bulmak çok kolay olacaktır. Ancak hangi modellerin kullanılacağını bilmek sizin için zor olabilir. Genetik programlama bu sorunu aşmak için büyük fayda sağlayacaktır. Genetik algoritmalar, Darwin’in Doğal Seleksiyon sürecinden esinlenmiştir ve bilgisayar biliminde optimizasyon ve arama sorunlarına çözüm üretmek için kullanılır.
Genel olarak, genetik algoritma üç kısımdan oluşur:
- Seçim: Belirli bir probleme ve uygunluk fonksiyonuna olası çözümlerden oluşan bir popülasyonunuz var. Her yinelemede, her çözümün uygunluk fonksiyonuna nasıl uyacağını değerlendirirsiniz.
- Çapraz geçişli: Sonra en uygun olanları seçin ve yeni bir popülasyon oluşturmak için çaprazlama yapın.
- Mutasyon: Çaprazlama sonucu gelen çocukları alıp rastgele bir modifikasyonla mutasyona uğratırsınız ve en uygun, en iyi çözümü elde edene kadar bu işlemi tekrarlarsınız.
Genetik algoritma, bilgisayar biliminde başlı başına devasa bir konudur. Eğer daha derine inmek isterseniz, bu video serisine göz atabilirsiniz.
Peki bunların hepsi veri bilimine nasıl uyuyor?
Doğru makine öğrenimi modelinin ve bu model için en iyi hiper parametrelerin seçilmesi genetik programlamanın kullanabileceği bir optimizasyon problemi olduğu ortaya çıkıyor. Scikit-learn üzerine inşa edilen TPOT, makine öğrenme hattınızı optimize etmek için genetik programlama kullanır. Mesela, makine öğrenmesinde, veriyi hazırladıktan sonra hangi özellikleri modelinize input olarak verileceğini ve bu özellikleri nasıl oluşturmanız gerektiğini bilmeniz gerekiyor. Bu özellikleri oluşturduktan sonra, bunları eğitmek için modelinize girersiniz ve sonra en iyi sonuçları almak için hiper parametrelerinizi ayarlarsınız. TPOT, deneme yanılma yoluyla tek tek yapmak yerine, bu adımları sizin için genetik programlama ile otomatik hale getirir ve bittiğinde sizin için en uygun kodu verir.
Daha iyi anlamak için, bir açık kaynak verisi üzerinde TPOT kütüphanesini kullanarak alıştırma yapacağız. Kullanacağımız veri seti, MAGIC Gama Teleskop veri kümesidir. Veriler, çeşitli görüntüleme teknikleri kullanılarak yer tabanlı bir atmosferik Cherenkov gama teleskobuna yüksek enerjili gama parçacıklarının kaydını simüle etmek için üretilir. Veri kümesi hakkında daha detaylı bilgi almak için bu bağlantıya göz atın. Veri kümesi aşağıdaki özelliklere sahiptir:
1- fLength: elips ana ekseni (sürekli)
2- fWidth : tali elipse ekseni
3- fSize: tüm piksellerin içeriklerinin toplamlarının log10’u
4- fConc: fSize üzerinde en yüksek iki toplamının oranı
5- fConc1: fSize üzerinden en yüksek piksel oranı
6- fAsym: ana eksene yansıtılan en yüksek pikselden merkeze olan mesafe
7- fM3Long: ana eksen boyunca üçüncü anın 3.kökü
8- fM3Trans: tali eksen boyunca üçüncü anın 3.kökü
9- fAlpha: orjinli bir vektör ile ana eksenin açısı
10- fDist: başlangıç noktasından elipsin merkezine kadar olan mesafe
11- class: g,h # gama(sinyal), hadron (hedef değişken)
Burada amacımız, sağlanan özelliklere göre gözlemin, sinyal olan gama mı yoksa arka plan gürültüsü olan Hadron mu olduğunu tespit etmektir.
Verileri okumak ve üzerinde hesaplamalar yapmak için pandas ve numpy kütüphanelerini yüklüyoruz.
import numpy as np import pandas as pd
pandas read_csv() fonksiyonu ile verisetimiz yüklüyoruz. Ayrıca, verisetinin sütun isimleri henüz olmadığından header = None parametresini de ekliyoruz.
df=pd.read_csv('https://archive.ics.uci.edu/ml/machine-learning-databases/magic/magic04.data',header=None)
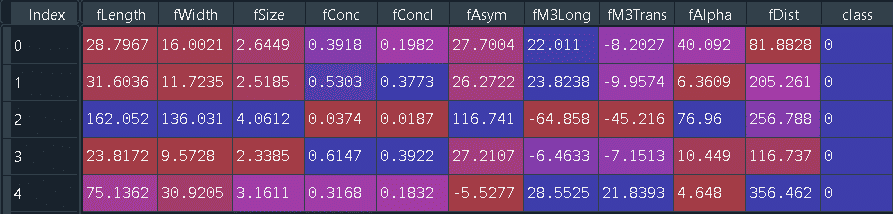
head() yöntemi ile verisetimizin ilk 5 satırını görebiliyoruz.
df.head()
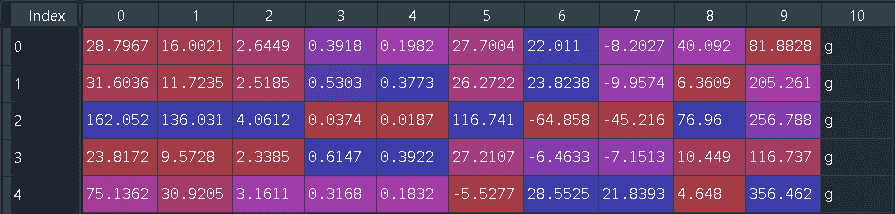
Sütun isimleri olmadığı, veri setine sütun isimlerini tanımlıyoruz.
df.columns = ['fLength', 'fWidth','fSize','fConc','fConcl','fAsym','fM3Long','fM3Trans','fAlpha','fDist','class']
describe() yöntemi ile sayısal değerlere sahip sütunların analizini yapabiliyoruz.
df.describe()
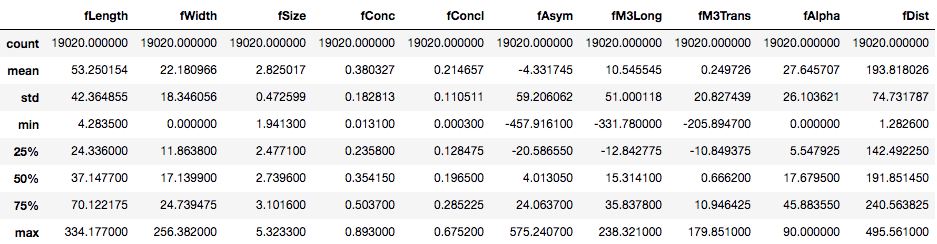
TPOT’u kullanmadan önce, DataFrame’inizde kategorik değişkenlerin etiketlemesini yapmanız önemlidir. Burada, hedef değişken kategorik özelliktedir(g ve h olmak üzere). G sınıfı 0 sayısal değeri ve h sınıfı 1 sayısal değeri ile değiştiriyoruz.
df['class']=df['class'].map({'g':0,'h':1})
df.head()
Ayrıca veri de herhangi bir kayıp değer var mı diye kontrol etmemiz lazım. Aşağıdaki kodu çalıştırarak bunu öğrenebiliriz.
pd.isnull(df).any() Output: fLength False fWidth False fSize False fConc False fConcl False fAsym False fM3Long False fM3Trans False fAlpha False fDist False class False dtype: bool
Bu veri seti herhangi bir kayıp veri içermiyor. Eğer içeriyor olsaydı, bu veri satırlarını ya dropna() yöntemi ile düşürecektik ya da fillna() ile bir değerle dolduracaktık.
Train ve Test
Şimdi veri setini train ve test olarak iki gruba ayırmamız gerekiyor.
from sklearn.cross_validation import train_test_split
training_indices, validation_indices = training_indices, testing_indices = train_test_split(tele.index,
stratify = df['class'].values,
train_size=0.75, test_size=0.25)
Sıra TPOT kütüphanesini kullanmaya geldi. TPOTClassifier bir çok parametre içerir, bunların detayını merak ediyorsanız buradan ulaşabilirsiniz.
from tpot import TPOTClassifier
from tpot import TPOTRegressor
tpot_classifier = TPOTClassifier(generations=5,verbosity=2)
tpot.classifier.fit(df.drop('class',axis=1).loc[training_indices].values,
df.loc[training_indices,'class'].values)
OUTPUT:
Optimization Progress: 33%|███▎ | 200/600 [41:43<1:51:41, 16.75s/pipeline]
Generation 1 - Current best internal CV score: 0.880266061124
Optimization Progress: 50%|█████ | 300/600 [1:14:37<46:57, 9.39s/pipeline]
Generation 2 - Current best internal CV score: 0.880266061124
Optimization Progress: 67%|██████▋ | 400/600 [1:59:17<2:21:21, 42.41s/pipeline]
Generation 3 - Current best internal CV score: 0.880266061124
Optimization Progress: 84%|████████▎ | 501/600 [3:01:12<1:02:16, 37.74s/pipeline] Generation 4 - Current best internal CV score: 0.881597992166
Generation 5 - Current best internal CV score: 0.881597992166
Best pipeline:
GradientBoostingClassifier(RobustScaler(PolynomialFeatures(input_matrix, degree=2, include_bias=False, interaction_only=False)), learning_rate=0.1, max_depth=6, max_features=0.6000000000000001, min_samples_leaf=12, min_samples_split=3, n_estimators=100, subsample=0.55)
TPOTClassifier(config_dict={'sklearn.ensemble.GradientBoostingClassifier': {'max_features': array([0.05, 0.1 , 0.15, 0.2 , 0.25, 0.3 , 0.35, 0.4 , 0.45, 0.5 , 0.55, 0.6 , 0.65, 0.7 , 0.75, 0.8 , 0.85, 0.9 , 0.95, 1. ]), 'learning_rate': [0.001, 0.01, 0.1, 0.5, 1.0], 'min_samples_leaf': [1, 2, 3, 4, 5, 6, 7... 0.6 , 0.65, 0.7 , 0.75, 0.8 , 0.85, 0.9 , 0.95, 1. ])}, 'sklearn.preprocessing.RobustScaler': {}}, crossover_rate=0.1, cv=5, disable_update_check=False, early_stop=None, generations=5, max_eval_time_mins=5, max_time_mins=None, memory=None, mutation_rate=0.9, n_jobs=1, offspring_size=100, periodic_checkpoint_folder=None, population_size=100, random_state=None, scoring=None, subsample=1.0, verbosity=2, warm_start=False)
Yukarda, her biri fiting modelinin eğitim setindeki eğitim verimliliğini veren 5 jenerasyon hesaplandı. Açıkça görüldüğü gibi, en iyi hat %88,16 CV doğruluk puanına sahip olan hattır. Bu sonucu üreten model, PloynomialFeatures ve ardından giriş verilerine sentetik özellikler ekleyen ve bunları normalleştiren RobustScaler gibi ön işleme tekniklerinden oluşan hattır ve daha sonra son tahminleri oluşturmak için bir Gradient Boosting sınıflandırıcısı tarafından kullanılır. Ayrıca tpot’un sınıflandırıcıyla birlikte learning_rate, max_depth, vb. gibi çeşitli hiper parametre değerleri verdiğini de fark edebilirsiniz.
Son olarak, TPOT’a, optimize edilmiş hatı için karşılık gelen Python kodunu dışa aktarma işlevine sahip bir metin dosyasına vermesini söyleyebilirsiniz:
tpot_classifier.export('tpot_MAGIC_Gamma_Telescope_pipeline.py')
OUTPUT:
True
## TPOT'un hazırlamış olduğu hat: tpot_MAGIC_Gamma_Telescope_pipeline.py
import numpy as np
import pandas as pd
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.model_selection import train_test_split
from sklearn.pipeline import make_pipeline
from sklearn.preprocessing import PolynomialFeatures, RobustScaler
tpot_data = pd.read_csv('PATH/TO/DATA/FILE', sep='COLUMN_SEPARATOR', dtype=np.float64)
features = tpot_data.drop('target', axis=1).values
training_features, testing_features, training_target, testing_target = \
train_test_split(features, tpot_data['target'].values, random_state=42)
# Score on the training set was:0.881597992166
exported_pipeline = make_pipeline(
PolynomialFeatures(degree=2, include_bias=False, interaction_only=False),
RobustScaler(),
GradientBoostingClassifier(learning_rate=0.1, max_depth=6, max_features=0.6, min_samples_leaf=12, min_samples_split=3, n_estimators=100, subsample=0.55)
)
exported_pipeline.fit(training_features, training_target)
results = exported_pipeline.predict(testing_features)
Harika değil mi? En iyi modeli elde etmek için parametrelerle uğraşmadan TPOT sizin için en iyi modeli vermekle kalmadı, aynı zamanda bunun için size çalışan bir Python kodu da verdi!
Buradaki tek sorun, TPOT’un çalışması saatler sürebilir. Bu süreyi kontrol etmek için değiştirmemiz gereken bazı parametreler vardır. Eğer bu süre sınırlanırsa, olası tüm hatları keşfedemeyecektir ve bu nedenle, kısıtlanan süre yüzünden size en iyi modeli veremeyebilir. Ancak yeterli zaman verilirse, mümkün olan en iyi modeli verecektir.
Limitleri
- Bütün yöntemleri keşfetmesi uzun zaman alabiliyor.
TPOT çalıştırmak aslında bu kadar basit bir işlem değil. Verinin bir çok ön işlemeden geçmesi gerekiyor. Bu nedenle yürütülmesi genellikle uzun zaman alır ve büyük veri kümeleri için pek mümkündür değildir. - Aynı veri seti için farklı çözümler sunabilir.
Yeterince karmaşık bir veri kümesiyle çalışıyorsanız veya TPOT’u kısa bir sürede çalıştırıyorsanız, farklı TPOT çalışmaları farklı önerilerle sonuçlanabilir. Çalışmalarınız zaman eksikliği nedeniyle yakınsanamadığı veya birden fazla hattın veri kümenizde aşağı yukarı aynı performansı gösterdiği anlamına gelir.