Kaggle Yarışmalarının En Popüler Algoritması: XGBoost


XGBoost, eXtreme Gradient Boosting anlamına gelir ve gradient boosted trees (gradyan artırılmış ağaçlar) algoritmasının açık kaynaklı bir uygulamasıdır. XGBoost, kullanım kolaylığı ve tahmin gücü nedeniyle Kaggle yarışmalarının en popüler makine öğrenmesi algoritması olmuştur. Genellikle regresyon ve sınıflandırma görevleri için kullanılabilen denetimli öğrenme algoritmasıdır.
Bu algoritmayı anlamak, birkaç kavramı öğrendikten sonra hiç zor gelmeyecektir. Söz konusu kavramlar ise karar ağaçları ve gradyan artırmadır. Eğer bu kavramlara zaten aşinaysanız “XGBoost nasıl çalışır?” bölümüne geçebilirsiniz.
Karar Ağaçları
Karar ağaçları, muhtemelen bulabileceğiniz en kolay yorumlanabilir makine öğrenmesi algoritmasıdır. Doğru tekniklerle kullanıldığı zaman çok güçlü bir algoritma haline dönüşebilir.
Çok sayıda yaprağı olan köklü bir ağaca benzediği için bu ismi almıştır. Bir örnek ile karar ağaçlarını daha iyi anlayalım. Titanik kazasındaki yolcuların yaşları, cinsiyetleri gibi bazı bilgiler ile bu kazadan kimin sağ kalıp kimin kalmadığını gösteren bir veri seti hayal edelim. Bu verilere dayanarak kimin hayatta kalacağını tahmin etmek için bir sınıflandırma modeli oluşturmak istiyorsak, ortaya şöyle bir görüntü çıkar.
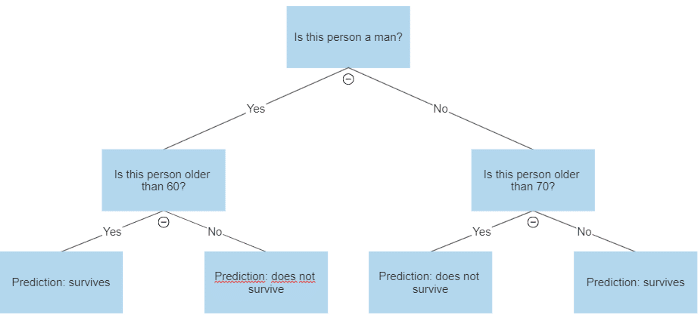
Yukarıdaki diagramda da görüldüğü üzere, karar ağaçları, istenilen değişkenin bir tahminini üreten basit kurallar dizisidir.
Gradyan Artırma
Artırma, ensemble (toplu) bir yöntemdir, yani birkaç modelden gelen tahminleri tek modelde birleştirmenin bir yoludur. Bu işlemi, her bir tahminleyiciyi sırayla alarak ve bir öncekinin hatasına göre modelleyerek (daha iyi performans gösteren tahminleyicilere daha fazla ağırlık vererek) yapar:
- Orijinal verileri kullanarak ilk modelinizi uydurun.
- Daha sonra ilk modelin kalıntılarıyla ikinci bir model uydurun.
- Model 1 ve 2’nin toplamını kullanarak üçüncü bir model oluşturun.
Gradyan artırma, bir gradient descent (gradyan iniş) algoritması kullanarak kayıp işlevini minimize eder.
XGBoost Nasıl Çalışır?
Karar ağaçları ve gradyan artırma anlaşıldıysa XGBoost’u anlamak çok daha kolay hale gelecektir. XGBoost, karar ağaçlarını “zayıf” tahminleyicileri olarak kullanan bir gradyan artırma algoritmasıdır. Bunun ötesinde, uygulaması optimum performans ve hız için özel olarak tasarlanmıştır.
Gözlemlere dayanarak, XGBoost, yapılandırılmış tablo verilerinde oldukça iyi bir performans göstermiştir. Buna nazaran eğer görüntü, ses gibi yapılandırılmamış verilerle uğraşıyorsanız, XGBoost yerine sinir ağları çoğu zaman daha iyi bir seçenek olmuştur.
Hiperparametreler
XGBoost’u uygularken seçilecek en önemli hiperparametreler hangileridir ve bunlar nasıl ayarlanır?
booster
booster, 3 seçeneğiniz olan artırma algoritmasıdır: gbtree, gblinear veya dart. Varsayılan seçenek, gbtree’dir. Dart, aşırı öğrenmeyi (over-fitting) önlemek için bırakma (dropout) tekniklerini kullanan benzer bir sürümdür. Gblinear ise, karar ağacı yerine genelleştirilmiş doğrusal regresyon kullanır.
reg_alpha and reg_lambda
reg_alpha ve reg_lambda, sırasıyla L1 ve L2 regülasyon terimleridir. Bu sayılar ne kadar büyükse, model o kadar tutucu ( aşırı öğrenmeye daha az eğilimli) olur. Her iki regülasyon terimi için önerilen değerler 0-1000 arasındadır.
max_depth
max_depth hiperparametresi, karar ağaçlarının maksimum derinliğini ayarlar. Bu sayı ne kadar büyük olursa model o kadar az tutucu hale gelir. 0 olarak ayarlanır ise, ağaçların derinliği için bir sınır söz konusu olmaz.
subsample
subsample, tahminleyicileri eğitirken kullanılacak örnek oranının boyutudur. Varsayılan değeri 1’dir, yani örnekleme yoktur ve tüm veriler kullanılır. Örneğin bu parametre, 0.7 olarak ayarlanırsa, gözlemlerin %70’i her artırma yinelemesinde kullanılmak üzere rastgele örneklenir. Aşırı öğrenmeyi önlemeye yardımcı olan bir parametredir.
num_estimators
num_estimators, kullanılacak olan artırılan ağaçların tur sayısını ayarlar. Bu sayı ne kadar büyükse, aşırı öğrenme riski de o kadar artar. Ancak düşük sayılar aynı zamanda düşük performansa da yol açabilir.
XGBoost Nasıl Kullanılır?
XGBoost’un pratikte nasıl çalıştığını göstermek için Python kullanarak bir Kaggle yarışmasında Titanic kazasından kurtulanları tahmin etmeye çalışarak basit bir egzersiz yapalım.
Verimizi Kaggle’dan indirdikten sonra, gerekli tüm kütüphaneleri içe aktaralım:
import pandas as pd
from xgboost import XGBClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
df = pd.read_csv("train.csv")
Eğer xgboost daha önceden bilgisayarınızda kurulu değil ise, terminalinizi açıp “pip install xgboost” komutunu çalıştırmanız gerekmektedir. Buradaki problemimiz bir sınıflandırma problemi olduğu için XGBClassifier’ı kullandık. Eğer problemimiz bir regresyon problemi olsaydı o zaman XGBRegressor kullanacaktık.
Verimiz de birçok değişken var fakat biz, bu problem için sadece “Sex” ve “Age” değişkenlerini kullanıyor olacağız.
sex_to_integer = pd.get_dummies(df['Sex']) df = pd.concat([df,sex_to_integer],axis=1) X = df[[‘Age’,’female’,’male’]] y = df[‘Survived’] seed = 42 test_size = 0.3 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=test_size, random_state=seed)
Yukarıdaki kod bloğunun ilk iki satırı String değer içeren Sex değişkenini sayısal değerlere ( 0 ve 1 ) çevirme işlemini yapar. Sonraki iki satır ise, hedef değişkenimizi ve onu tahmin etmek için kullanacağımız değişkenleri tanımlar. Son 3 satır ise, veri setimizin eğitim ve test olarak bölünmesiyle alakalıdır.
model = XGBClassifier(subsample = 0.7, max_depth = 4) model.fit(X_train, y_train) print(model) y_pred = model.predict(X_test) accuracy = accuracy_score(y_test, y_pred) print(“Accuracy: %.2f%%” % (accuracy * 100.0)) ÇIKTI: XGBClassifier(base_score=0.5, booster='gbtree', colsample_bylevel=1, colsample_bynode=1, colsample_bytree=1, gamma=0, learning_rate=0.1, max_delta_step=0, max_depth=4, min_child_weight=1, missing=None, n_estimators=100, n_jobs=1, nthread=None, objective='binary:logistic', random_state=0, reg_alpha=0, reg_lambda=1, scale_pos_weight=1, seed=None,silent=None, subsample=1, verbosity=1) Accuracy: 80.60%
Yukarıdaki kod bloğunun ilk iki satırında verimizi XGBoost ile eğitiyoruz. Bazı hiperparametleri manuel olarak tanımladık. Mevcut parametreler ile %80.60’lık bir doğruluk oranı elde ettik. Siz de dilediğiniz gibi bu parametreleri değiştirip farklı doğruluk oranları elde edebilirsiniz. Kaggle yarışmalarının en popüler algoritması olan XGBoost, çalışma mantığı ve gerçek verilere uygulanması açısından gayet basit olsa da, burada fark yaratacak şey, hiperparametre ayarı ve öznitelik mühendisliğidir.